第33章 语义层工程¶
场景引入¶
第32章已经说明,DataAgent 长期直连 ODS 物理表会把业务口径暴露给模型猜测。用户问“上周华东销售下滑的主要 SKU 是什么”,系统需要先处理“销售”“华东”“上周”这三个词。销售可能是运营 GMV,也可能是财务不含税 GMV;华东可能来自组织主数据,也可能来自历史区域划分;上周可能按自然周,也可能按企业财务周。语义层的作用,是把这些容易漂移的业务含义固定下来。数据平台团队在语义层中维护指标、维度、Join、默认过滤、权限和版本;DataAgent 在运行时调用语义层,把 Question Frame 中的口语槽位绑定到可执行对象。这样模型负责规划和表达,语义层负责事实口径。
经营会议里最常见的数据争议,常常落在“你说的这个数到底怎么算”。同一句“销售额”,运营团队可能指含促销调整的 GMV,财务团队可能指不含税收入,区域团队可能把退货算到下周,电商团队又按支付时间统计。每个口径在自己的场景里都可能成立,但如果 DataAgent 只凭表名和列注释生成 SQL,就会把这些差异压扁成一个看似确定的字段。一次真实问数链路通常会经过多个含义转换。用户说“上周华东销售下滑”,系统要先把“销售”识别为候选指标,把“华东”映射到组织主数据,把“上周”展开为企业认可的业务周,再判断当前用户能看到哪些明细。任何一步出错,SQL 都可能正常执行,结果却不被业务承认。更麻烦的是,这类错误不一定在数据库层报错。查询返回了数字,图表也画出来了,直到会议上有人对账,问题才暴露出来。
语义层要解决的正是这种“SQL 正确但业务错误”的风险。它把物理表之上的指标、维度、Join 路径、权限、版本和默认过滤整理成机器可执行的业务模型。DataAgent 维护独立指标定义,或者在 Prompt 里临时解释 GMV 公式,都会让同一指标在系统间分裂。模型可以帮助理解用户语言、选择候选对象和生成说明,但最终口径必须来自语义层的 Metric、Dimension、View 和 Glossary。
语义层远不止给数据库加中文注释。中文注释能帮助模型猜字段含义,却无法表达生效时间、适用角色、默认过滤、数据新鲜度、血缘和质量状态。DataAgent 需要这些信号来决定是否回答、是否追问、是否拒答,以及回答里应该如何写口径和限制条件。一个成熟系统在给出数字时,至少要能说清楚用了哪个 metric_id@version,数据同步到什么时候,当前用户是通过哪个 View 获得访问权限的。这里采用 DataAgent 消费侧视角。第15章已经从数据平台视角讨论元数据和指标建设,下面不再重复建设流程,而关注 DataAgent 在一次 Run 中如何读取语义层、如何消歧,以及如何把可信上下文带入回答和 Trace。
33.1 语义层作为可信问数地基¶
语义层是在物理表之上的业务抽象。它集中定义 Measure、Dimension、Hierarchy、View、Join 路径和访问策略,并通过 SQL、REST、GraphQL 或产品 API 暴露给上层应用。Cube、MetricFlow 和 dbt Semantic Layer 都属于这一类实践。如果没有语义层,DataAgent 生成 SQL 时会同时面对口径、Join 和权限三类不稳定因素。销售额是否含税、是否扣退货、是否包含促销调整,决定了指标口径;事实表和维表关系是否被正确约束,决定了结果是否重复或漏算;同一张物理表中可能同时包含可公开指标和敏感字段,模型直接选表很容易越权。
表33-1:无语义层时的风险与语义层提供的约束。来源:本书整理。
| 问题 | 无语义层时的风险 | 语义层约束 |
|---|---|---|
| 指标口径 | 模型自行猜 GMV 定义 | Metric 定义和版本 |
| Join 路径 | 物理表随意 Join | 预建模关系和 View |
| 权限 | 直接暴露敏感列 | 行列权限和角色视图 |
| 新鲜度 | 不知道数据同步时间 | 元数据和质量信号 |
给表写中文注释只是语义层的起点。注释能解释列名,但表达不了聚合公式、默认过滤、版本、权限和 Join 图。DataAgent 需要可执行 Metric,也不能只看一段描述性文本。Memory 适合记录用户上次确认了“用同比展示”或“默认看华东区”,指标数学定义仍要回到语义层版本。如果把 GMV 公式写进长期 Memory,组织调整或会计政策变化后,DataAgent 很容易继续使用旧口径。
语义层的价值还体现在跨产品一致性上。BI 看板、DataAgent 问数、定时报告和告警系统如果分别维护指标定义,短期开发会更快,长期对账会非常痛苦。平台化 DataAgent 应尽量消费同一套语义层。为了让模型“更好理解”而复制一份 Agent 专用 YAML,会让 GMV、毛利和收入这类核心指标在多个系统中分叉。Agent 可以有自己的提示词和问法策略,指标数学定义则应保持统一。
建设侧和消费侧要分工明确。数据平台团队负责模型发布、指标审批、血缘和质量;DataAgent 团队负责把用户语言映射到这些模型,并把结果解释给业务用户。DataAgent 可以向数据平台反馈“哪个术语经常歧义”“哪个指标缺少 title”“哪个 View 太大导致 Linking 噪声”。修表和改口径仍要经过数据平台流程,否则线上问数会绕过已有的数据治理责任。
33.2 Metric、Dimension、View 与 Glossary¶
DataAgent 消费语义层时,最常接触四类对象。Metric 定义可聚合指标,例如运营 GMV、订单量、毛利率。Dimension 定义切片属性,例如区域、品类、渠道、SKU。View 定义某类用户可见的指标和维度集合。Glossary 定义业务术语到语义对象的映射,例如“营业额”“销售额”“GMV”可能对应多个 Metric。
表33-2:语义层对象与 DataAgent 用法。来源:本书整理。
| 对象 | 作用 | DataAgent 用法 |
|---|---|---|
| Metric | 指标公式、默认过滤、版本 | 绑定 Question Frame 中的指标槽位 |
| Dimension | 过滤、分组、下钻字段 | 绑定时间、区域、SKU 等维度 |
| View | 角色或场景可见范围 | 限制 Planner 可见对象 |
| Glossary | 业务术语映射 | 把用户口语转成候选 Metric |
每个 Metric 至少应有程序 ID、展示标题、定义、owner、版本和默认过滤。展示标题很重要,因为它会进入用户回答。只写“GMV 下降 12.3%”会留下口径疑问;写成“运营 GMV gmv_ops@2025Q1 下降 12.3%”,用户才能知道系统采用的是哪套口径。把整个仓库 DDL 交给 Planner,会让上下文变长,也会增加错误联想。更可靠的做法是分层裁剪:用户登录后按角色注入 View 摘要;Linker 根据问题召回少量候选 Metric 和 Dimension;Join、默认过滤和 SQL 编译交给语义层 API 完成。这样能控制上下文长度,也能减少模型把无关表拉进查询的机会。
view: sales_ops
metrics:
- gmv_ops
- gmv_tax_excluded
- order_count
dimensions:
- region_code
- category
- sku
- week
上面这段摘要只告诉 Planner “当前角色可以围绕哪些对象规划”。它不是完整语义层模型,也不包含所有物理 Join 细节。完整定义仍由 infra/semantic_layer/ 的 API 持有。View 的粒度要适合角色,而非只适配数据库结构。运营总监需要看到区域、品类、SKU、渠道和经营 GMV;财务 Controller 需要看到毛利、成本和不含税收入;门店经理可能只能看到自己负责的门店。一个过大的 View 会让 Linker 候选过多,一个过小的 View 又会导致用户频繁被拒答。View 的设计应根据业务角色和常见问题持续调整。
Glossary 是持续维护的业务词表。业务术语会变化,用户会使用简称、别名和口语表达。例如“营收”“销售额”“流水”“GMV”在不同企业中可能不同。Glossary 应记录同义词、适用范围、候选 Metric 和默认策略,并把高频澄清问题反馈给数据治理流程。缺少 Glossary 时,模型只能依赖表名和列名猜测业务含义,稳定性很差。Metric 的 title 和 description 会进入 DataAgent 的回答、追问和 Trace,不能按普通文档字段随手填写。标题过于工程化,例如 gmv_ops_v2,业务用户无法理解;描述过于营销化,又无法支撑审计。比较好的写法是短标题加精确定义,例如“运营 GMV:含促销调整,按订单创建时间统计,扣除部分退单”。这类文本既能给模型消歧,也能给用户解释。
33.3 Schema Linking 与字段消歧¶
Schema Linking 是把 Question Frame 中的口语槽位绑定到语义层对象和必要物理 schema 的过程。用户说“销售下滑”,Frame 里可能只有 metrics: [gmv] 和 task_type: diagnose;Linker 要进一步判断这个 gmv 对应哪个 Metric、哪个版本、哪些维度和过滤条件。
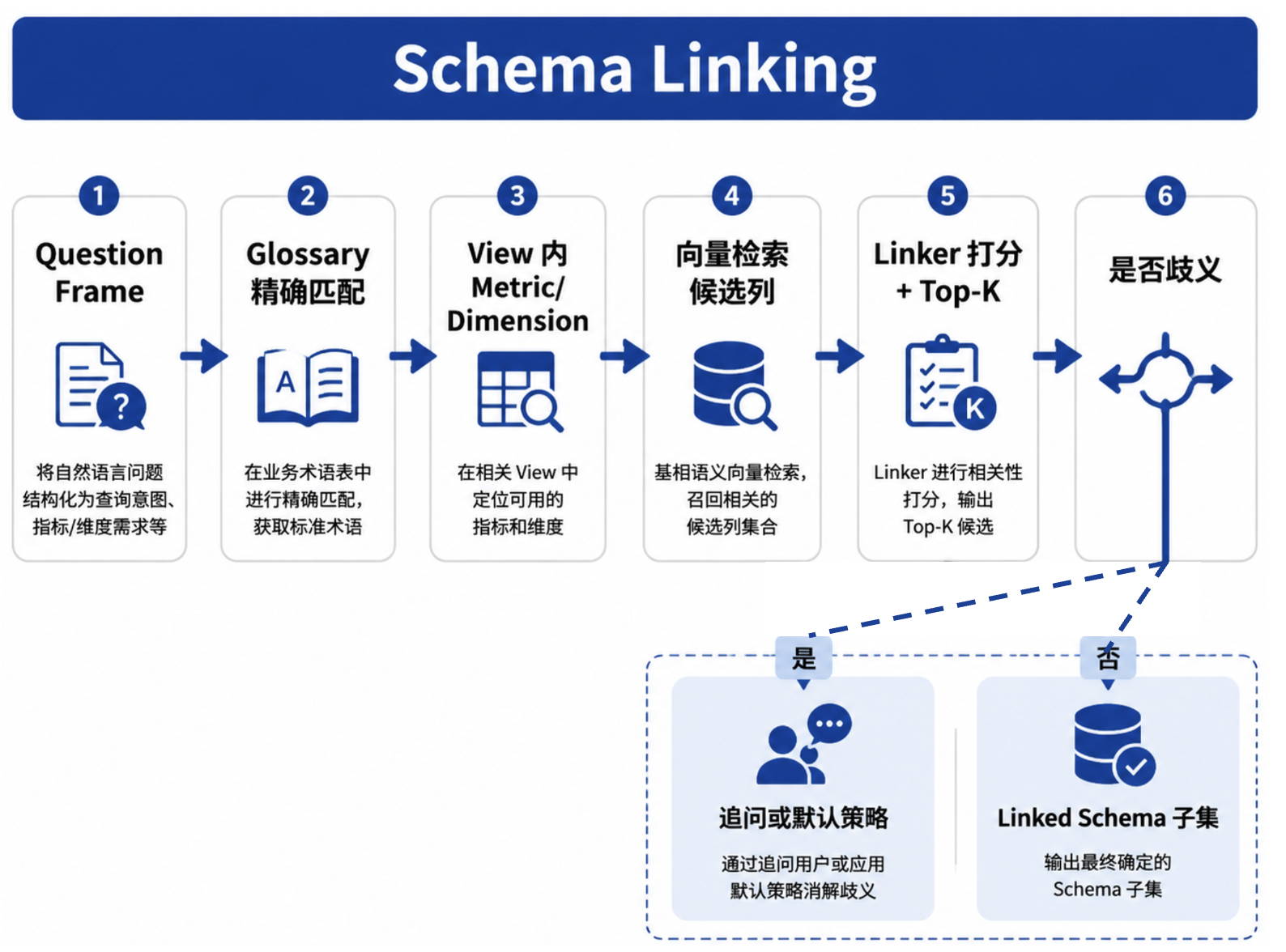
图33-1:Schema Linking 模式链接流程。来源:本书自绘。Alt text:流程从用户问题出发,经术语识别、候选字段召回、按信号打分、消歧确认,输出绑定到具体 Metric 与字段的 Linked Schema。
Linking 通常按三步完成。第一步用 Glossary 找候选对象,例如“销售额”“GMV”命中运营 GMV 和财务 GMV。第二步用 View 过滤,把当前用户无权使用或当前场景不适用的对象排除。第三步在允许范围内用向量检索、历史成功 Run 和列注释召回候选字段,再按规则或模型 rerank。
表33-3:Linking 信号来源。来源:本书整理。
| 信号 | 优先级 | 说明 |
|---|---|---|
| Glossary | 高 | 业务术语到候选 Metric |
| View | 高 | 当前角色和租户可见范围 |
| 向量检索 | 中 | 在允许范围内召回字段 |
| 历史成功 Run | 中 | 需校验 Metric 版本 |
| 模型自由推断 | 低 | 必须经过 schema 校验 |
沿用第32章的华东下滑问题,Linker 会先把“销售”识别为 GMV 候选,再用 sales_ops View 和用户角色收窄范围。如果仍存在两个合法口径,就要追问或采用角色默认,并在回答中明示。随后,“华东”通过组织层级映射为 region_code = 'EAST',“SKU”绑定到当前 View 允许的商品维度。
{
"metrics": [{"metric_id": "gmv_ops", "version": "2025Q1", "title": "运营 GMV"}],
"dimensions": ["region_code", "sku"],
"filters": [{"field": "region_code", "op": "eq", "value": "EAST"}],
"time_range": {"grain": "week", "range": "last_week"},
"view": "sales_ops"
}
Linking 失败通常表现为查询合法但口径错误,而非 SQL 语法错误。比如链接到废弃列、跨 View 组合字段、把同名不同义字段当成同一维度。DataAgent 应把候选、得分、最终选择和消歧原因写入 Trace,便于第38章回放。Linking 还需要评测集。评测样本除了工程师编写的标准问题,还要包含真实用户说法、缩写、错别字、跨部门叫法和需要拒答的边界问题。每个样本至少标注期望 Metric、Dimension、View、是否需要追问,以及必须排除的错误候选。这样才能发现模型看似答对 SQL、实际选错口径的问题。历史成功 Run 可以作为 Linking 的候选信号,但必须带版本校验。上个月某个用户问过“华东销售”,系统成功使用了 gmv_ops@2025Q1,这只能说明当时的绑定有效。如果语义层升级到 2025Q2,历史 Run 只能进入候选集,最终绑定仍要按当前版本和 View 重新确认。向量检索也要限制范围。把全库列名和注释都放进向量库,召回相似字段很容易;但如果不先按 View、租户和权限过滤,模型可能看到不该看的字段。正确顺序是先过滤可见范围,再在可见范围内召回和 rerank。检索负责辅助消歧,权限仍由语义层和 Policy 控制。
33.4 指标冲突、版本与适用范围¶
企业里经常存在多个合法口径。财务团队可能维护不含税 GMV,运营团队可能维护含促销调整的运营 GMV;总部可能有集团口径,区域团队可能有本地口径;2024 年和 2025 年的定义也可能不同。DataAgent 如果把这些冲突隐藏起来,用户会以为系统返回的是唯一事实。
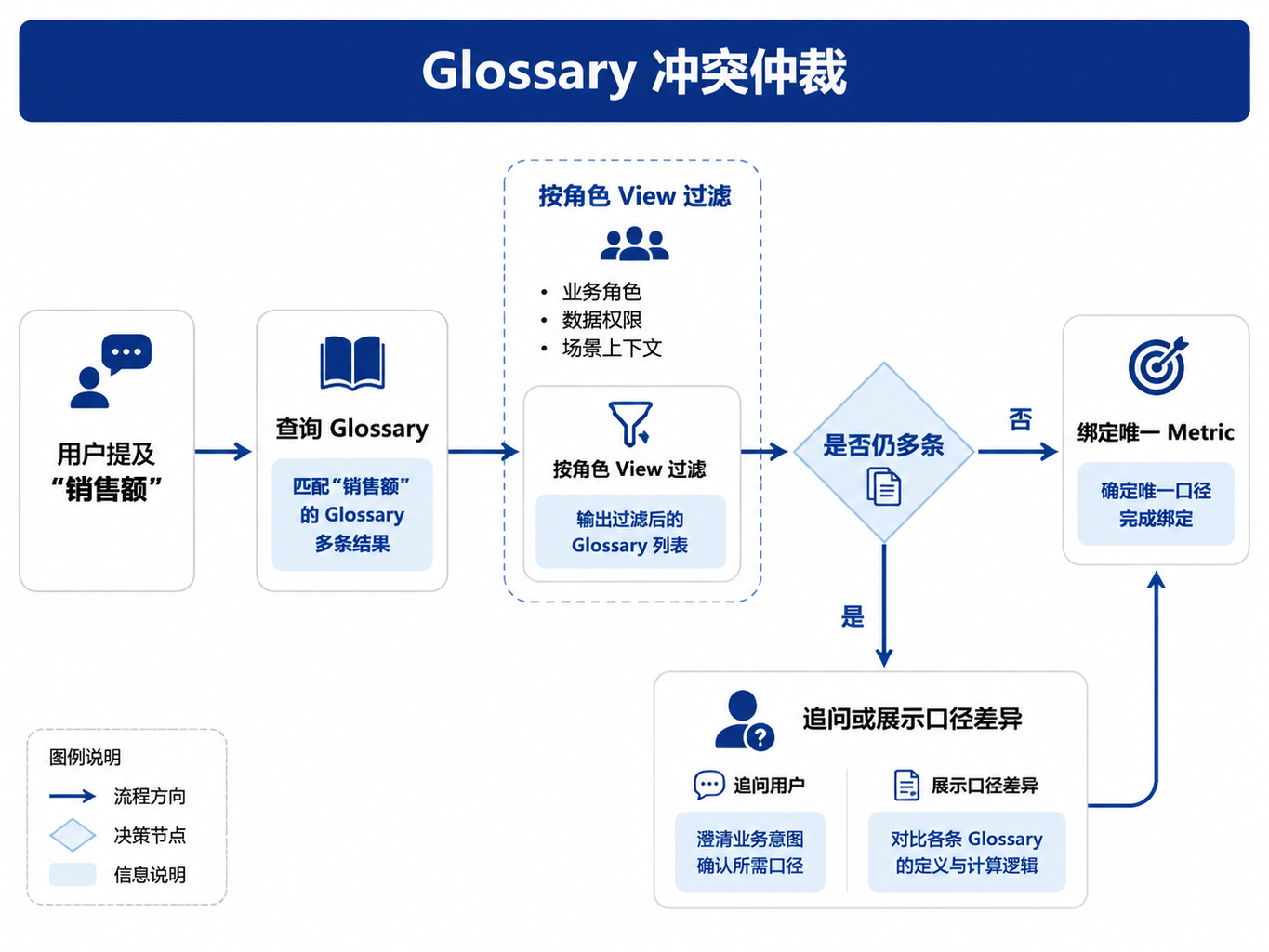
图33-2:Glossary 多 Metric 消歧流程。来源:本书自绘。Alt text:当一个术语匹配多个 Metric 时,流程按视图作用域、用户角色、历史偏好逐步缩小候选,必要时向用户追问。
表33-4:指标冲突时的处理策略。来源:本书整理。
| 情况 | 处理方式 | 用户可见表达 |
|---|---|---|
| View 过滤后唯一 | 自动选择 | 写出指标 title 和版本 |
| 同一 View 下仍有多个 | 追问或使用默认 Metric | 说明默认来源 |
| 指标版本跨期 | 使用生效期匹配 | 标注 metric_id@version |
| 无安全匹配 | 拒答或转人工 | 说明缺少可用口径 |
版本解决“同一指标随时间演变”的问题,适用范围解决“同一指标对谁有效”的问题。Run 中至少要记录 metric_id、version、生效时间、View、租户和默认过滤。用户追问“你刚才用的是哪个 GMV”时,系统应能直接回答,不要重新解释一遍自然语言。强制全公司只有一个口径,能减少对话复杂度,但在多业务线企业中经常不现实。允许多口径并存,则必须把选择过程显性化。更危险的是后台多口径并存,前台却只显示“销售额”。这种做法短期体验简单,长期会让 DataAgent 和正式报表无法对账。
指标版本变更要影响 DataAgent 的行为。新版本发布后,简单覆盖旧定义会破坏历史报告复现,未完成 Run 也可能仍在使用旧版本。比较稳的方式是新旧版本并存一段时间,语义层返回版本生效期,Planner 按问题的时间范围和当前 View 选择版本。跨版本对比时,系统应标注“口径发生变更”,必要时要求人工确认。用户默认策略也要可审计。运营总监默认使用运营 GMV,财务 Controller 默认使用财务 GMV,这种默认来自组织策略,而非模型偏好。策略来源、版本和适用角色应写入 Trace。否则同一句“销售额”在不同用户那里得到不同数字时,平台无法解释差异来源。当冲突无法消解时,拒答比错答更好。DataAgent 可以说“当前语义层中存在两个销售额口径,请选择运营 GMV 或财务 GMV”,也可以提供简短差异说明。用户完成选择后,系统再继续执行。这样的交互会多一步,但能避免把口径分歧埋进最终数字。
33.5 可信上下文:权限、血缘、质量和新鲜度¶
指标口径回答“数字怎么算”,可信上下文回答“用户能不能看、数据从哪来、质量如何、同步到什么时候”。DataAgent 只返回数字时,用户无法判断结果能不能进入会议材料;必要的权限、血缘、质量和新鲜度信号应写入回答脚注和 Trace。
表33-5:可信上下文的来源与用途。来源:本书整理。
| 维度 | 来源 | DataAgent 用途 |
|---|---|---|
| 权限 | 语义层 RBAC、Policy | 执行前拦截越权查询 |
| 血缘 | OpenLineage、DataHub、元数据服务 | 说明数据来源和模型版本 |
| 质量 | dbt tests、Great Expectations | 质量异常时降低结论强度 |
| 新鲜度 | 分区时间、同步任务状态 | 标注数据截至时间或拒答 |
一次华东下滑分析中,trusted_context() 可能返回 View、policy 引用、底层表、模型版本、质量状态和最大同步时间。Planner 不需要把这些原始 JSON 全部展示给用户,但应转成必要的自然语言脚注。例如“数据来自 orders_fact v3,截至 2025-06-14 06:00 同步;SKU 空值率略高,下钻结论仅供参考。”如果新鲜度超过 SLA,系统可以拒答、提示重试,或进入 HITL 等人确认是否仍展示。多源查询时,还要避免只标注最快的数据源;更可靠的做法是取最差新鲜度,或分别标注关键数据源的同步时间。可信上下文要与 Memory 分开命名。Memory 可以记录用户偏好同比展示,Org Context 可以记录区域组织口径,语义层负责 Metric 定义和版本,元数据服务负责质量和新鲜度。把这些来源混在一个“上下文”字段里,容易让模型把偏好当事实,把旧记忆当口径。
可信上下文在回答中的呈现要有层次。普通查询不必展示完整血缘图,但至少应说明指标口径和数据时间;质量异常时应加一句限制条件;正式报告应把血缘、质量状态和执行 SQL 放到附录或审计面板。展示过多会打扰业务用户,展示过少会削弱信任。产品上可以把简短脚注放在正文,把完整证据放在可展开区域。质量信号还要影响结论强度。如果 SKU 空值率略高,系统可以继续回答 Top 品类,但应弱化 SKU 级结论;如果事实表延迟超过 SLA,系统应拒绝生成“最新”结论;如果血缘中某个上游任务失败,报告应进入人工确认。可信上下文会改变 Planner 是否继续、如何表达和是否需要 HITL。
多源查询尤其需要谨慎。一个问题可能同时读取订单表、退货表和促销表。每个数据源的新鲜度和质量状态不同,回答中应展示整体可用性。只展示状态最好的数据源,会让用户误以为所有数据都处在同一时间截面。对于经营分析,通常应取最保守的同步时间,或者明确说明“订单数据截至 06:00,退货数据截至 04:00”。
33.6 语义层接口与 DataAgent 查询链路¶
mini-platform 中,语义层目标接口位于 infra/semantic_layer/,DataAgent 的 Linker 位于 agents/data_agent/。当前仓库中部分实现仍是目标契约,本章重点是接口形状和依赖方向。
mini-platform/infra/semantic_layer/
├── client.py
├── models/
└── __init__.py
mini-platform/agents/data_agent/
└── linker.py
resolve_metric() 负责把口语指标解析为候选 Metric;compile_query() 负责把已消歧的 Metric、Dimension、filter 和 time range 编译成可执行查询;trusted_context() 负责返回权限、血缘、质量和新鲜度。Planner 可以读取结果,Measure 聚合逻辑则由语义层保持不可改写。
{
"metrics": ["gmv_ops"],
"dimensions": ["region_code", "sku"],
"filters": [{"field": "region_code", "op": "eq", "value": "EAST"}],
"time_range": {"start": "2025-06-09", "end": "2025-06-15", "grain": "week"},
"view": "sales_ops",
"tenant_id": "demo-tenant"
}
生产落地时,至少要守住四条线:生产查询经语义层 View,避免 DataAgent 长期直连物理表;Metric 变更有版本、owner 和审批记录;Linking 日志保留候选和最终选择理由;新鲜度或质量异常要能影响回答,不能只写进后台日志。常见故障也集中在这些边界。View 过大时,Linking 仍会超出上下文,需要按意图生成子 View;IAM 未注入 semantic_view 时,应拒答,降级到全库会放大越权风险;历史成功 SQL 的 Metric 版本过期时,需要重新校验版本;Cube 或 MetricFlow 冷启动超时时,应让 Run 失败或重试,不能让模型绕过语义层直接写物理 SQL。
落地时可以先实现一个窄接口,不必一次性接完整语义层产品。早期只需要支持核心 Metric、常用 Dimension、角色 View、Glossary 和 compile_query();等问数链路稳定后,再接入更多血缘、质量和复杂 Join 能力。接口要保持稳定,底层可以从自研 YAML 逐步迁移到 Cube 或 MetricFlow。测试也要围绕接口做。resolve_metric() 测歧义和拒答,compile_query() 测默认过滤和 View 限制,trusted_context() 测质量和新鲜度异常,Linker 测候选召回和版本一致性。只测最终 SQL 是否能执行,覆盖不到语义层最关键的风险。
语义层变更还要有发布纪律。新增 Metric、废弃别名、修改默认过滤、调整 View 权限,都会改变 DataAgent 的回答。每次变更都应生成影响范围:哪些金标准问题会受影响,哪些报告模板引用了该 Metric,哪些用户默认策略需要更新。变更发布后,旧 Run 仍按旧版本回放,新 Run 才使用新版本。否则用户在复盘上月报告时,看到的可能是今天的口径解释。运营上,语义层团队需要定期查看 DataAgent 失败样本。高频澄清说明 Glossary 不够清楚;高频拒答说明 View 设计过窄或权限提示不够明确;高频口径投诉说明 Metric 标题、默认策略或回答脚注需要改。DataAgent 除了消费语义层,也会把真实业务问法反馈回数据治理。
33.7 语义层进入生产链路的验收标准¶
语义层进入 DataAgent 生产链路后,就不再只是指标字典。它要同时服务 NL2SQL、权限过滤、结果解释、血缘追踪和评测集构建。一个指标是否可用,除了看公式能否编译,还要看版本、适用范围、维度约束、数据新鲜度和负责人是否明确。否则模型即使找到了指标名,也无法判断该指标是否适合当前问题。语义层与 NL2SQL 的关系要保持单向约束。NL2SQL 可以根据用户问题选择指标、维度和过滤条件,口径来源必须是已登记的 Metric;执行引擎可以编译 SQL,敏感明细访问仍要经过语义层和 Policy。这样的限制会让早期能力显得保守,却能减少“SQL 能跑但业务不认”的问题。
权限也应在语义层阶段尽早介入。若模型先看到完整 schema,再在执行前过滤权限,敏感表名、字段名和业务含义已经进入上下文和 trace。更稳的方式是先按用户、租户、数据域生成可见 Linked Schema,再交给 NL2SQL。这样模型只能在允许范围内生成查询,后续 Policy 仍负责执行前二次校验。验收还要包含“解释是否可被业务复核”。很多语义层测试只检查 SQL 是否编译,或者指标公式是否返回数值。DataAgent 还需要把指标标题、版本、默认过滤和数据时间写给用户看。业务用户读到“运营 GMV gmv_ops@2025Q1”时,应能知道它和财务收入不同;审计人员回放 Run 时,应能看到这个版本当时为什么适用。解释不可复核的语义层,即使编译正确,也很难支撑生产问数。语义层还要反哺评测。每次 NL2SQL 失败,都应标注失败原因:术语未覆盖、指标版本冲突、字段解释不足、权限过滤后候选缺失,还是模型选择错误。只有把这些原因回写到 Glossary、Metric 和 View 的治理流程,DataAgent 才会越用越稳。否则评测只会告诉团队“答错了”,不会告诉团队该修语义层还是修 prompt。
33.8 语义层变更的回归治理¶
语义层一旦进入生产,就要像软件版本一样发布。一个指标公式、维度枚举或字段别名的变化,会影响 NL2SQL 生成、历史报告复现、评测集结果和用户对口径的理解。平台应把语义层变更当成可发布对象:有版本、有评审、有回归、有灰度,也有回滚路径。最容易出问题的是“看似同义”的业务词。经营团队把“GMV”改成“成交额”,财务团队把“净收入”调整为扣除返利后的口径,区域团队把“华东”从销售组织改成履约组织,这些变化都可能让历史问题得到不同 SQL。模型不会天然知道口径变更背后的组织语义,它只会在可见上下文里选择最相近的解释。因此,Glossary 的别名、Metric 的版本和 View 的适用范围必须一起发布。
语义层回归样本应覆盖三类问题。第一类是稳定问题:原本能回答的问题,在口径变更后仍应得到同样业务含义的结果,或明确提示口径发生变化。第二类是边界问题:用户请求不在当前权限、时间范围或组织范围内时,系统应拒绝或澄清,选择相近字段凑出答案会制造错误信心。第三类是解释问题:结果返回后,报告应能说明使用了哪个指标版本、哪些过滤条件和哪些数据快照。这套治理会增加语义层发布成本,但能避免更昂贵的返工。没有版本治理时,DataAgent 的错误常表现为“SQL 没错,但业务不认”。有了回归治理,团队可以把争议定位到具体口径:是术语没有覆盖,是指标版本不对,是权限过滤改变了候选 schema,还是模型在多个合法口径之间选错了。问题被拆开之后,才有可能持续改进。
33.9 语义层与权限链路的共同设计¶
语义层经常被当成数据建模问题,权限则被当成安全系统问题。DataAgent 上线后,这两件事必须一起设计。模型看到的字段、指标和维度,已经会影响后续生成 SQL 的可能空间。如果权限只在 SQL 执行前拦截,模型仍可能在 prompt、trace 或错误消息中暴露用户无权知道的字段含义。更稳的方式,是在 Linked Schema 阶段就生成“按用户裁剪后的语义视图”。裁剪后的语义视图除了删表删字段,还要同步调整解释文本。一个用户看不到客户手机号字段时,字段说明、示例 SQL 或指标解释里也不应暴露它的业务含义。一个租户不能访问某区域数据时,维度枚举和示例问题也要随之收缩。否则模型虽然无法执行越权 SQL,却可能通过解释文本泄露组织结构或数据存在性。
这会影响语义层缓存设计。许多系统希望把 schema context 缓存在模型侧或应用侧,以减少延迟;但语义上下文一旦和用户权限绑定,全局复用就会带来越权风险。平台可以缓存公共指标定义和字段元数据,但最终进入模型的 Linked Schema 应按租户、角色、数据域和时间窗口生成,并记录版本。第38章的 Trace 至少要能说明某次 Run 使用了哪份语义视图,而非只记录“使用了语义层”。
权限链路还要支持业务解释。用户无权查看明细时,系统如果只返回技术报错,用户不知道下一步该申请权限还是改问聚合指标。更好的回答是说明可以查看的聚合层级、可申请的权限路径,或可转人工的处理方式。这样 DataAgent 不会因为安全边界变得不可用,也不会为了体验牺牲治理。语义层在这里承担的是“可见能力说明”的角色:告诉模型和用户,在当前权限下可以问到什么程度。
33.10 语义层变更的发布纪律¶
语义层一旦进入 DataAgent 主链路,就要按发布对象处理。指标口径、维度层级、同义词、字段别名和权限标签的变化,都会改变 NL2SQL 的候选空间,也会改变报告层对结果的解释方式。很多问数事故并非模型突然变差,而是语义层发生了未被评测覆盖的变化:一个字段从订单日期改成出库日期,一个指标把退款排除口径调整到新的状态码,或者一个业务词在不同数据域里被复用。读者在设计平台时,要把这些变化当成可发布的软件变更,而非后台运营人员随手维护的词表。
语义层发布至少需要经过三类校验。第一类是静态校验,检查指标引用的字段是否存在、聚合函数是否与字段类型匹配、时间粒度是否能向下钻取、权限标签是否完整。第二类是回归样本校验,把历史高频问题、事故问题和业务审核问题重新跑一遍,比较生成 SQL、执行结果、解释文本和 EvidenceRef 的变化。第三类是影响面校验,标出哪些 Agent、报表、数据产品和评测集会受到影响。只有三类校验都能留下记录,语义层版本才适合进入灰度。
灰度发布只看回答是否“看起来正确”,会漏掉 schema linking 和解释层的变化。平台应当记录旧版本和新版本在同一批问题上的 schema linking 结果、SQL 差异、执行耗时、返回行数和指标解释差异。对于数值变化,审核人需要知道变化来自口径调整、数据刷新、权限收缩还是生成错误。对于解释变化,审核人需要看到 EvidenceRef 是否仍然指向同一组指标和数据来源。这样做会增加发布检查,但能让 DataAgent 的行为变化可定位。没有这层纪律,后续第34章的 NL2SQL 校验、第38章的 Trace 回放和第39章的评测都只能看到现象,很难追到根因。
33.11 语义层在事故复盘中的定位¶
DataAgent 回答错误时,团队容易把问题直接归因于模型。但在生产环境里,语义层通常要先被排查。一个完整的复盘应当从用户原始问题开始,依次查看术语识别、数据域选择、指标匹配、维度过滤、权限裁剪、SQL 生成和报告解释。只要其中一个环节没有版本记录,复盘就会停在猜测层面。语义层工程的价值,正是在这些环节之间提供可检查的中间状态。事故复盘还要区分“语义层定义错误”和“语义层覆盖不足”。前者需要修正指标或字段关系,并触发历史样本回归;后者需要增加同义词、业务术语、示例问题或数据域说明。两类问题的修复方式不同,全部交给 Prompt 调整只会掩盖责任边界。Prompt 可以提示模型更谨慎,指标治理和权限系统仍要在语义层中完成。平台把复盘结论回写到语义层时,也要保留来源:来自业务审核、线上投诉、评测集失败还是数据质量告警。来源不同,置信度和发布节奏也不同。
在第32章的总体架构里,语义层处在用户问题和执行系统之间;在第38章的 Trace 体系里,它又是每次 Run 的中间证据。把这两层视角合起来,语义层就重点落在 DataAgent 可治理性的入口,问数知识库只是其中一部分。它既决定模型能看到什么,也决定平台事后能解释什么。早期系统可以先从少量核心指标做起,但必须从一开始就保存版本、样本和发布记录,否则后面很难补齐可信问数所需的证据。
33.12 语义层与数据质量的联动¶
语义层负责暴露数据质量状态,数据质量治理本身仍由数据平台承担。用户问“本月收入为什么下降”时,如果底层明细表延迟、维度表缺失、指标刷新失败或异常值未处理,DataAgent 给出确定解释会误导决策。语义层应把数据新鲜度、质量规则、异常告警和适用范围提供给 NL2SQL 和报告层,让回答在证据不足时保持克制。数据质量状态还涉及查询生成。某个指标当天未刷新,系统可以改用上一个完整账期,也可以要求用户确认是否接受未完成数据;静默混用新旧数据会让结果难以复核。某个维度质量不稳定,系统应避免把它作为归因结论的唯一依据。语义层把这些约束写进上下文,模型才有机会生成合适的查询和解释。这类联动让语义层从“指标字典”升级为“可信上下文服务”。它向上服务自然语言理解,向下连接数据治理,横向连接权限和质量。DataAgent 的可信度往往取决于这些上下文是否完整,而非模型是否更会写 SQL。
质量状态还要有用户可理解的表达。后台告警可以写成分区延迟、唯一性校验失败、外键缺失或空值率超阈值;业务回答直接抛出这些技术词,用户仍然不知道结果能不能用。更合适的表达是说明影响范围,例如“订单数据已同步到今天 06:00,但退货数据延迟到 04:00,本次毛利分析暂不用于关账判断”。这类表达让业务知道结果能用到什么程度,也让平台保留了证据。
质量信号还涉及自动化程度。数据新鲜度正常、指标版本稳定、权限清楚时,DataAgent 可以自动完成只读问数;质量异常但仍可参考时,系统可以生成带限制说明的草稿;质量严重异常时,系统应拒绝生成正式结论,并把任务转给数据负责人或等待刷新。把质量状态接入 Runtime 后,DataAgent 才能根据证据强弱调整任务路径,而非一律生成流畅答案。从组织协作看,语义层团队也需要固定的反馈入口。业务用户发现口径不符,DataAgent 应能记录问题对应的 Metric、View、用户角色和原始问法;数据团队修正后,应能看到哪些验收样本因此变化。这样语义层维护不再是后台文档工作,而是 DataAgent 生产运营的一部分。
语义层和数据质量的关系,还要落到责任分工上。数据平台团队负责质量规则、同步任务和血缘信息,DataAgent 团队负责把这些状态转成任务决策和用户表达,业务团队负责判断某个质量问题是否影响本次决策。比如退货数据延迟两小时,在日常经营看板里可能可以接受,在财务关账里则必须停止生成结论。平台不能替业务判断影响程度,但要把足够清楚的状态交给业务和审批人。
质量异常还应进入后续改进。某个指标反复因为上游同步延迟导致 DataAgent 拒答,说明问题可能不在问数产品,而在数据链路 SLA;某个维度反复空值率过高,说明语义层需要调整可下钻范围;某类报告经常因为质量限制被退回,说明模板应把风险提示放得更靠前。DataAgent 的失败样本能把这些问题暴露出来,语义层团队需要把它们纳入数据治理工作,不能只修自然语言映射。
最终,可信问数依赖的是一组共同工作的系统。模型负责理解和生成,语义层负责口径和可见范围,元数据服务负责质量和新鲜度,执行器负责只读和资源保护,Trace 负责回放。任何一层缺失,用户都可能看到一个表达顺畅但无法复核的数字。本章把语义层放在 DataAgent 主链路中讨论,就是为了让读者看到这些责任如何连接起来。语义层还要处理“局部正确”的问题。一个指标在总部经营会中定义清楚,在区域经营会上却可能需要额外过滤加盟门店;一个品类维度在零售业务中稳定,在供应链分析里却需要映射到仓库分类。DataAgent 如果只拿一个全局定义到处使用,就会在局部场景里答错。系统要把 Metric、View、角色和场景组合起来判断。全局口径解决一致性,场景 View 解决适用性,两者缺一不可。
这种设计会让语义层比传统指标字典更复杂。它需要同时有给人看的解释,也要有给机器执行的约束;需要同时支持稳定指标,也要允许某些业务域保留差异;需要同时让 DataAgent 少追问,又要在口径冲突时明确停下来。团队在早期可以只覆盖少量高频指标,但这些指标必须从一开始就包含 owner、版本、生效范围、默认过滤和质量信号。否则后续扩展到更多数据域时,早期的宽松做法会变成系统性风险。
评审语义层时,业务负责人也要参与。工程团队能判断字段是否存在、SQL 是否能编译、权限标签是否完整,却不一定能判断“销售额”在某个会议场景中应不应该扣除退货。业务负责人确认口径后,DataAgent 才能把默认策略写入 Profile 或 View。这个过程看起来像治理流程,实际是在为模型减少自由猜测空间。语义层还应承担培训作用。业务用户第一次看到 DataAgent 的回答时,往往会先看结论,再追问“这个销售额是哪一个销售额”。如果回答脚注、指标标题和可展开说明都来自同一套语义层,用户会逐渐形成稳定预期:什么问题可以直接问,什么问题需要先确认口径,什么结果只能作为草稿参考。这种预期建立以后,系统使用成本会下降,数据争议也更容易被定位到具体指标或版本。
语义层会直接进入产品体验、会议讨论和审计复盘,不再是后台工程资产的附属物。团队在设计 DataAgent 时,应把语义层当成用户信任的一部分来维护,而非只在 SQL 生成失败时才回头补字段说明。早期落地时,可以少做指标,但责任字段要齐。每个上线指标至少要有 owner、适用场景、默认时间口径、权限范围和版本说明。范围窄一点,系统仍然能建立信任;责任字段缺失,后续每次争议都会回到人工解释。
33.13 语义层运营中的口径争议处理¶
语义层上线后,口径争议会持续出现。同一个“活跃客户”“新增收入”“流失率”,在销售、财务、运营和管理层之间可能有不同解释。DataAgent 把这些指标放进自然语言回答后,争议会变得更明显,因为用户看到的是一句确定结论。平台需要把争议处理做成语义层运营的一部分,而不是在每次投诉后临时解释。
争议处理应从样本开始。每次用户质疑指标,平台记录用户问题、使用指标、语义层版本、SQL、数据快照、回答文本、争议原因和最终裁定。若争议来自字段选择错误,修 schema linking;若来自指标定义冲突,修语义层版本和适用范围;若来自数据延迟,修新鲜度提示;若来自业务口径不统一,则需要业务 owner 裁定。不同原因对应不同修复路径,不能全部归为模型理解错误。
语义层还要保存历史裁定。某个指标口径在六月改变后,五月的回答仍应能按当时版本解释。用户复盘历史会议材料时,平台不能用当前口径覆盖旧结果。语义层运营的质量,体现在它能让 DataAgent 的答案随业务更新,同时保留历史答案的解释能力。
33.14 语义层样本池的分层维护¶
语义层样本池要分层维护,否则很快会变成一堆难以使用的问句。第一层是基础覆盖样本,验证核心指标、常用维度、默认时间范围和权限裁剪能正常工作;第二层是业务争议样本,来自用户质疑、会议复盘和口径裁定;第三层是事故样本,记录曾经导致错误回答、错误 SQL 或错误解释的问题;第四层是发布样本,用来评估语义层版本变更对关键任务的影响。不同样本的 owner、发布门槛和复审周期不同,不能全部放进同一个“问数测试集”。
样本池还要保存中间过程,最终答案只是其中一项。一个样本应记录用户原话、识别出的业务术语、候选 Metric、候选 View、最终选择、被过滤的字段、生成 SQL、执行结果、解释文本和 EvidenceRef。这样当样本失败时,团队能判断问题发生在术语识别、schema linking、权限裁剪、SQL 生成还是解释层。只保存“正确答案”会让回归变成黑盒测试,修复效率很低。
分层样本能帮助团队控制发布成本。核心指标每次发布都要跑,低频业务争议可以按月复审,历史事故样本在相关语义对象变化时触发,探索性样本可以留在观察池。这样语义层发布不会被无关样本拖慢,也不会因为样本太少而漏掉高风险变化。对于早期平台,先维护少量高质量样本,比追求覆盖所有问法更有价值。
样本池最终要服务协作。业务 owner 用样本确认口径,数据团队用样本发现质量和血缘问题,平台团队用样本验证 Linking 和 Trace,评测团队用样本判断 DataAgent 行为是否稳定。样本池把“口径是否对”这类讨论变成可复现材料,减少了纯靠会议解释的成本。语义层能否长期稳定,取决于这些样本是否持续更新,而不是指标 YAML 是否写得整齐。
33.15 语义层变更的用户沟通¶
语义层变更会直接改变用户理解数据的方式。指标定义调整、默认时间口径变化、维度归属修正、废弃字段下线、权限规则收紧,都会让同一个问题得到不同回答。若平台只在后台更新 YAML 或指标配置,用户会把变化理解成 Agent 不稳定。语义层发布需要用户沟通,让业务方知道哪些问题会受影响,历史答案如何解释,新答案从什么时候生效。
用户沟通不等于把所有技术细节暴露出去。更合适的方式是给高频指标和关键业务域提供简短变更说明:变更对象、旧口径、新口径、影响范围、生效时间、历史结果处理方式和联系人。DataAgent 在回答受影响问题时,可以在脚注中提示“本指标已在某日期更新口径”,并提供展开说明。这样用户能把数字变化和口径变化联系起来,而不是反复质疑模型和数据。
沟通还要进入产品交互。对低风险指标,系统可以在回答后显示变更提示;对高风险经营指标,系统应在生成正式报告前要求确认口径;对历史会议材料,系统应保留当时语义层版本,不用当前口径覆盖旧结论。若用户追问“为什么和上个月不同”,DataAgent 应能从语义层变更记录中取到解释,而不是重新编写一个看似合理的原因。
早期可以先为核心指标建立语义层变更公告。公告进入指标详情页、DataAgent 回答脚注和报告发布记录。每次公告都关联样本回放和业务 owner 裁定。这样语义层不会只是后台配置,而会成为用户信任和组织沟通的一部分。
33.16 语义层变更的用户沟通¶
语义层变更会直接改变 DataAgent 的回答。指标口径调整、维度层级变化、字段别名修改、权限规则更新、血缘修正,都可能让同一个自然语言问题生成不同 SQL 或不同解释。若用户只看到答案变化,很难判断平台是否变好,还是口径发生了变化。语义层变更需要用户沟通机制,而不是只在数据团队内部发布。
沟通内容要面向任务。用户不需要阅读完整字段 diff,但需要知道哪些问题会受到影响,旧口径和新口径的差异是什么,历史报告是否需要重新生成,哪些场景进入过渡期。对于经营分析类任务,平台可以在回答中提示“该指标已在某版本调整口径”;对于正式报告,系统应要求重新引用新的 EvidenceRef;对于自动审批,变更期间可以暂停自动结论。
早期可以为语义层发布生成变更摘要:影响指标、影响维度、典型问题、样本回放结果、历史 artifact 处理方式和业务 owner 确认。摘要进入 DataAgent 上下文和报告页提示。这样语义层会从 NL2SQL 内部配置扩展为业务用户可理解的分析口径管理工具。
33.17 语义层变更的影响预估¶
语义层进入生产后,新增能力不能只看功能是否可用,还要看运行证据能否被不同角色复用。平台需要把指标依赖、下游问题、样本覆盖、权限变化、发布时间和用户通知记录成稳定字段,并和发布单、Trace、评测样本以及事故记录关联起来。这样一次线上问题发生后,团队可以沿着同一组事实判断影响范围、责任归属和修复顺序,而不是在模型日志、业务日志和人工说明之间来回拼接。
这类证据还要服务相邻章节的能力。它和第34章 NL2SQL、第36章报告和第39章 Eval相连:上游能力提供输入假设,下游能力使用执行结果,治理能力负责保存证据和复审结论。若这些材料没有统一编号和版本,章节里讨论的工程能力在生产中会被拆散。业务 owner 只能看到用户投诉,平台 owner 只能看到系统错误,安全或合规团队只能看到事后说明,最后很难判断问题到底来自数据、模型、工具、流程还是组织责任。
生产环境中常见的风险包括指标口径改变后旧问题继续命中、新权限未进入生成链路、报告解释和 SQL 结果不一致。这些问题在演示阶段不明显,因为演示通常只覆盖成功路径;上线后,用户会带来边界问题、重复请求、权限变化和长时间运行状态。平台团队应把失败样本纳入发布节奏,记录哪些样本需要阻断发布,哪些样本可以通过降级处理,哪些样本需要业务 owner 接受剩余风险。
语义层变更应先做影响预估,再进入样本回放和业务通知。这份记录不需要复杂,但要包含时间、版本、owner、样本、处置动作和下次复查条件。没有这些字段,复盘会停留在口头经验;有了这些字段,平台才能把一次问题转成后续发布、评测和培训材料。
早期平台可以从少量高风险场景开始。先选择调用量高、业务影响大或涉及敏感数据的路径,要求每次变更都留下证据包,再逐步推广到普通场景。这样章节里的能力不会停留在概念层,而会成为可运行、可解释、可退回的工程系统。
本章小结¶
语义层是 DataAgent 可信问数的地基,负责指标、维度、Join、权限和版本。DataAgent 应消费 Metric、Dimension、View 和 Glossary,而非把全库 DDL 直接塞进模型上下文。Schema Linking 要在 Glossary、View、向量检索和历史 Run 之间做消歧,并把选择过程写入 Trace。指标冲突不能被隐藏,Run 和回答都应记录 metric_id@version、View 和默认来源。权限、血缘、质量和新鲜度属于可信上下文。它们应进入回答脚注和审计回放,让用户知道数字来自哪里、是否有权查看、口径是否稳定。
参考文献¶
Cube. (2025). Introduction: Cube semantic layer. https://cube.dev/docs/product/introduction
dbt Labs. (2024). About MetricFlow. dbt Developer Hub. https://docs.getdbt.com/docs/build/about-metricflow
Liu, X., et al. (2025). A survey of Text-to-SQL in the era of LLMs. IEEE TKDE, 37(10), 5735-5754. https://doi.org/10.1109/TKDE.2025.3592032
Lei, F., et al. (2024). Spider 2.0: Evaluating language models on real-world enterprise text-to-SQL workflows. ICLR 2025. arXiv:2411.07763. https://arxiv.org/abs/2411.07763
Talaei, S., et al. (2024). CHESS: Contextual harnessing for efficient SQL synthesis. arXiv:2405.16755. https://arxiv.org/abs/2405.16755
OpenLineage. (2024). OpenLineage documentation. https://openlineage.io/docs/