第18章 向量数据库与索引算法¶
向量数据库承接 RAG 中的检索执行。Embedding 生成、答案判断、权限裁决和血缘解释仍由其他组件负责。向量库接收向量、metadata 和索引参数,在权限、延迟、召回质量和成本之间做工程折中。如果平台团队一上来只问“Milvus、Qdrant、pgvector、Weaviate 选哪个”,就已经跳过了更重要的问题:数据规模多大,查询是否需要强过滤,是否多租户,是否要求事务一致性,是否能接受索引重建窗口,是否需要和传统搜索合并。
向量库事故通常不会以“数据库坏了”的形式出现。更常见的是业务用户看到一段无权文档的影子,DataAgent 召回了过期字段,客服助手引用了旧制度,或者模型升级后同一个问题突然命中另一批 chunk。排障时团队才发现,向量记录里没有源文档版本,metadata 里缺少部门权限,索引没有绑定 embedding 模型,检索日志只保存了最终答案。系统看起来在正常返回结果,实际已经失去可解释性。这也是向量库和普通缓存的区别。缓存错了可以清掉,向量索引错了会影响召回、引用、评测和审计。一个文档解析修复后,旧 chunk 是否仍在索引里;一个字段权限变化后,旧向量是否还带着旧 ACL;一个 embedding 模型升级后,新 query 是否还在打旧索引;一个租户删除数据后,评测样本和重排缓存是否同步清理。这些问题都落在向量库生命周期里,而非单纯的 ANN 算法选择。
企业语义检索还要面对成本压力。维度越高,内存和存储越贵;top-k 越大,重排和上下文组装越重;metadata filter 越复杂,召回和延迟越难兼顾;索引副本越多,灰度和回滚越稳,但成本也会上升。HNSW、IVF、PQ、DiskANN 等路线都要放进同一张工程账单里评估:召回率、p95、内存、构建时间、删除延迟、回滚窗口和团队运维能力缺一不可。只看算法名称会遮住真正的风险,因为同一个 HNSW 配置在无过滤公开数据集上表现很好,到了带租户、部门和生效时间过滤的企业数据里,可能完全不是同一条曲线。
本章讨论向量数据库、ANN 索引、HNSW、元数据过滤、多租户权限和向量库选型。读者需要把向量库看成知识基础设施:它保存向量,也保存版本、权限、来源、过滤条件和回放证据。选型结论应来自当前规模、权限要求、运维能力和成本边界,而不是来自某个数据库的宣传指标。一个适合早期平台的向量库,未必是公开 benchmark 里最强的系统;它更可能是能稳定完成过滤、回放、删除、灰度和成本治理的组件。
18.1 向量库平台定位¶
企业向量库应作为平台组件管理,不能停留在某个应用的私有缓存。知识库、客服、法务、DataAgent、推荐去重都可能共享 embedding 服务和向量索引能力,但它们的权限、更新频率和质量目标不同。平台层要提供统一的写入契约、查询契约、版本契约和观测指标。DataAgent 对向量库的要求和普通知识库不同。字段、指标、SQL 示例、报表截图和业务术语经常来自不同系统,更新频率也不同;字段级权限和租户隔离要进入 metadata filter;同一个业务问题还可能同时检索语义层、历史 SQL、数据质量规则和指标血缘。因此 DataAgent 的向量库更接近语义层候选索引,按普通文档索引处理会漏掉口径、字段和权限约束。
如果这层边界没有设计清楚,事故通常不会表现成“向量库故障”,而会表现成更难追查的业务错误。一个常见路径是:某个部门的制度片段因为 metadata 缺少 department_id 被写入共享 collection,检索时又只做 post-filter,服务日志和 trace 里已经记录了无权候选;模型即使没有把内容完整说出来,候选片段也已经进入了不可见用户的排障链路。另一个路径是索引没有绑定 embedding 模型版本,模型升级后新旧向量混在一起,召回结果突然偏向历史样例,DataAgent 生成 SQL 时沿用了过期字段。平台层的职责,是把这些风险提前变成 schema、过滤、版本和观测约束。讨论选型前,先要像表18-1 一样划清向量库的职责边界,尤其要写清楚它“不负责什么”。否则团队很容易把 embedding 生成、权限系统、答案正确性和数据血缘都塞给向量库。
表18-1:向量库在企业平台中的职责。来源:本书整理。
| 职责 | 说明 | 不负责什么 |
|---|---|---|
| 向量索引 | 管理 embedding、metric、index type、namespace、版本 | 不负责生成 embedding |
| metadata 过滤 | 按租户、部门、权限、生效时间、文档状态过滤 | 不替代统一权限系统 |
| 近似检索 | 在延迟和召回之间折中 | 不保证最终答案正确 |
| 生命周期治理 | 重建、双写、灰度、回滚、压缩和归档 | 不替代数据血缘与审计 |
| 观测与成本 | 记录 QPS、p95、召回、过滤命中、索引大小 | 不解释业务语义错误 |
职责边界确定后,平台负责人才能做选型判断。这里关注“什么时候该建设共享平台、什么时候可以用轻量方案”,不单纯比较数据库品牌。中小规模、强 SQL/事务/元数据需求的场景,通常可以先用 pgvector 起步;当多个业务共享索引、大规模检索和高 QPS 成为主要矛盾时,再评估 Milvus、Qdrant 或 Vespa。是否建设统一向量平台,也不取决于技术偏好,而取决于多个业务是否共同需要 embedding、索引、权限、评测和回滚。单应用试点没有必要提前平台化,但一旦知识库、DataAgent 和客服助手开始共用索引能力,就要把 collection、版本和过滤字段纳入统一治理。
安全和成本是选型时最容易被低估的两条线。安全上,高风险场景不允许无权候选进入模型、日志或 trace,因此 pre-filter 通常比 post-filter 更稳。成本上,维度、索引类型、过滤策略、top-k 和 reranker 都会影响内存和延迟,不能只看向量库标称 QPS。最小治理要求也要提前写清:每个索引都应记录 embedding 模型版本、chunk 策略、metadata schema、构建时间、评测结果和回滚窗口。先定义平台边界,再把边界转成投入决策。没有这个顺序,团队很容易一上来讨论 Milvus 或 pgvector,却没有说清楚谁负责索引版本、权限过滤和回滚。放到图 18-1 的平台位置中看,向量库的核心接口是带着 metadata、权限、版本和指标完成可治理检索,而非简单存一条向量。

图18-1:向量库在企业 Agent 平台中的位置。来源:本书自绘。Alt text:分层图中向量库位于嵌入服务之下、RAG 与知识助手之上,存储向量与元数据并对外提供带权限过滤的检索接口,标出其"可检索知识存储"职责。
平台化之后,这些能力还要能像图 18-2 那样被运维和治理界面管理。多租户、collection、索引版本、过滤字段和观测指标如果都散落在各应用配置文件里,向量库就很难成为共享平台能力。
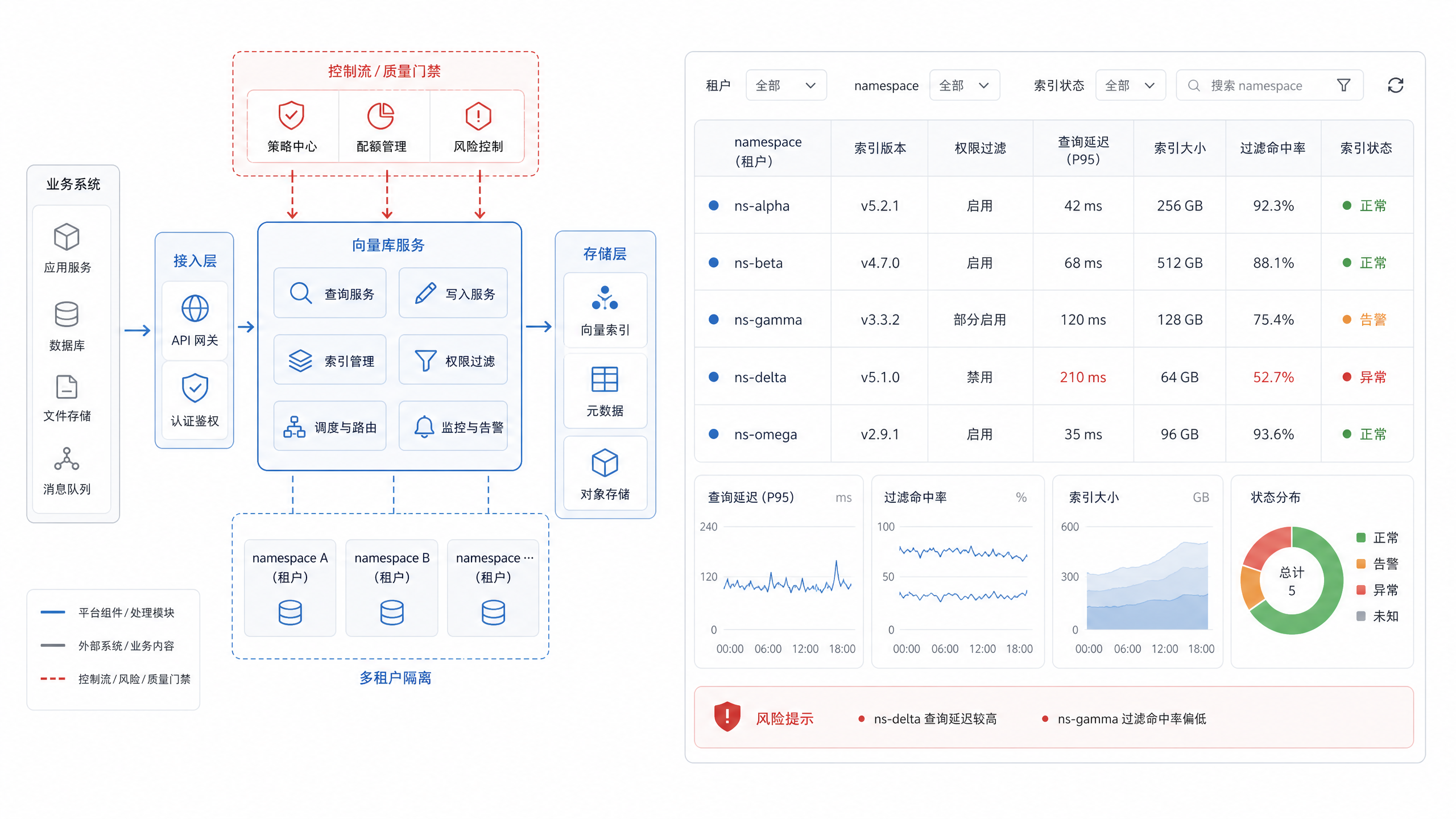
图18-2:企业向量库多租户控制台。来源:产品界面截图。Alt text:控制台界面展示按租户划分的集合列表、向量规模、索引类型与权限配置,体现向量库以租户为单位做隔离与配额管理。
18.2 ANN 索引算法谱系¶
向量检索的核心难点是规模。少量向量可以精确计算相似度;百万、千万、亿级向量就要用 Approximate Nearest Neighbor,牺牲一点召回换取可接受的延迟和成本。Milvus、Qdrant、Weaviate、Vespa、pgvector 等系统暴露的索引名称不同,但底层取舍大体围绕图索引、倒排聚类、量化压缩和磁盘索引展开。理解 ANN 时,先用表18-2 建立共同的算法语言,比直接给出唯一答案更重要。HNSW、IVF、PQ、磁盘索引和精确检索分别对应不同的内存、构建、召回和延迟取舍。
表18-2:ANN 索引算法谱系。来源:本书整理。
| 算法路线 | 直觉 | 优势 | 代价 |
|---|---|---|---|
| HNSW | 构建多层近邻图,查询时沿图搜索 | 召回和延迟表现稳定,工程生态成熟 | 内存占用较高,构建参数影响明显 |
| IVF | 先把向量聚类到桶,再在少量桶内搜索 | 大规模数据可控,适合配合压缩 | 需要训练聚类中心,参数不当会漏召回 |
| PQ/SQ 量化 | 用低比特表示近似向量 | 节省内存和存储 | 分数精度下降,需要重排或精排补偿 |
| DiskANN / 磁盘索引 | 用磁盘和缓存承载更大索引 | 降低内存压力 | 延迟抖动、冷热数据和硬件配置更敏感 |
| 精确索引 | 暴力或数据库原生精确距离计算 | 结果可解释,适合小规模 baseline | 数据量大时不可扩展 |
企业不必在第一天追求最复杂的索引。更可靠的路线是小规模数据用精确或 HNSW 建 baseline,拿内部 query 集测 recall@k 和 p95;规模上来后再评估 IVF/PQ、分片、磁盘索引和冷热分层。索引参数不是一次性配置,它会和 embedding 模型、维度、metadata 过滤、top-k、reranker 一起变化。内部 query 集要来自真实任务,不能临时写几十个自然语言问题充数。向量库的召回错误往往只在边界问题上暴露:字段名相似但含义不同、合同条款编号相近、制度版本相互覆盖、用户问题同时带时间和权限约束。HNSW 的 ef_search 调高后召回可能改善,但 p95 和内存也会上升;IVF 的聚类桶设置不当时,热门问题看起来正常,长尾实体却会漏召回;量化压缩节省成本,却可能让相近指标或相似条款的分数顺序颠倒。这些取舍不能靠默认参数判断,必须用带标签的 query 集和失败样例回放来确认。选型讨论应从召回、内存、构建时间和延迟开始,而不应停留在算法名。图 18-3 的索引谱系把这些取舍放在同一张图里,方便团队先对齐问题,再讨论具体实现。
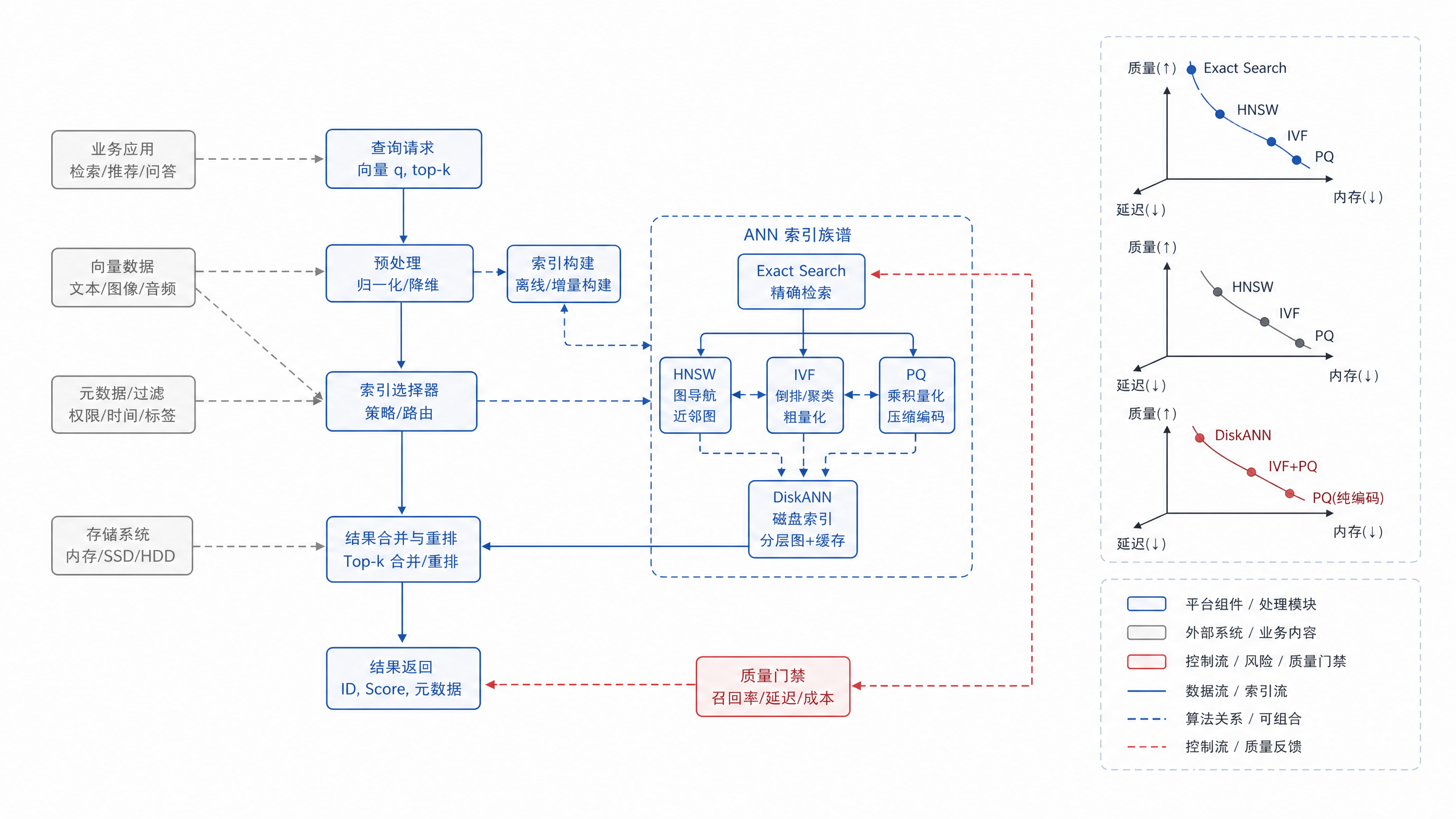
图18-3:ANN 索引算法谱系图。来源:本书自绘。Alt text:树状谱系把 ANN 索引分为基于图(HNSW)、基于量化(IVF-PQ)、基于树/哈希等分支,每个叶子标注召回、延迟、内存特征,展示索引家族关系。
18.3 主流向量库技术选型¶
主流向量库的差异不只在索引算法。pgvector 的优势是和 PostgreSQL 数据、事务、SQL 权限靠得近;Milvus 更偏大规模向量基础设施;Qdrant 强调 payload/filter 和服务化向量检索;Weaviate 提供 schema、向量化模块和 GraphQL/REST 能力;Vespa 更像搜索与推荐平台,适合复杂 ranking;Chroma 更适合原型和轻量开发。
表18-3 回到企业约束比较工具路线,并延续前面的职责边界和索引取舍。这里不讨论“谁最好”,而是判断谁更适合当前规模、权限模型、运维能力和 mini-platform 的演进阶段。
表18-3:主流向量库路线取舍表。来源:本书整理。
| 方案 | 优势 | 代价 | 适用场景 | mini-platform 选择 |
|---|---|---|---|---|
| pgvector | 和 PostgreSQL 结合紧密,SQL、事务、权限和元数据管理简单 | 超大规模和复杂 ANN 能力不如专门向量库 | 中小规模知识库、DataAgent 字段检索、团队已有 PostgreSQL | 默认 baseline,适合 Project 13 起步 |
| Milvus | 面向大规模向量检索,索引类型和分布式能力丰富 | 运维组件更多,治理成本较高 | 大规模知识库、多业务共享向量平台 | 作为大规模候选进入 benchmark |
| Qdrant | payload filtering 和服务化 API 友好,易做多租户过滤 | 需要额外管理数据库与业务系统的一致性 | 多租户 RAG、权限过滤强的场景 | 作为服务化候选进入 benchmark |
| Weaviate | schema、模块化向量化、检索 API 完整 | 与既有数据平台集成需要评估 | 快速构建语义搜索和知识应用 | 作为产品化候选调研 |
| Vespa | 搜索、推荐、ranking 表达力强 | 学习曲线和部署复杂度高 | 大规模搜索推荐、复杂排序、多阶段 ranking | 作为高级搜索平台候选 |
选型时不要只问“支持 HNSW 吗”。还要追问:metadata filter 在 ANN 前后如何执行,过滤会不会严重降低召回;索引重建能否不停服;租户隔离是 namespace、collection、partition 还是业务字段;备份恢复是否覆盖向量和 metadata;查询日志能否追溯到用户、索引版本和候选列表。对企业平台来说,轻量方案和专用向量库之间没有固定答案。早期如果数据量不大、团队已有 PostgreSQL 运维经验,pgvector 往往能更快把事务、权限和备份纳入同一套体系;当索引规模、写入吞吐、多业务隔离和重建窗口成为主要矛盾时,专用向量库才会显示优势。选型评审应要求候选方案跑同一批数据、同一批 query、同一套 filter 和同一套回滚流程,不能拿各自最漂亮的演示结果对比。
还有一个容易忽略的问题:向量库和企业现有搜索系统的关系。很多公司已经有 Elasticsearch、OpenSearch、OLAP 搜索或数据目录检索,向量库不一定要替代它们。更常见的路线是混合检索:关键词检索负责编号、字段、专有名词和精确条件,向量检索负责语义相似和模糊表达,reranker 再统一排序。若团队直接把所有检索迁到向量库,短期看起来架构简单,长期会在精确匹配、权限过滤和可解释性上付出代价。
混合检索的工程难点在合并结果。BM25 找到的是精确词和编号,向量召回找到的是语义近邻,数据目录可能返回字段和指标对象。平台需要统一候选 ID、来源、分数、权限和证据片段,再交给 reranker 或规则排序。否则前端看到的是几路结果拼接,Trace 里也解释不清某个证据为什么排在前面。向量库选型时,要看它能否和这些已有系统组成稳定链路,单库召回只是其中一个指标。因此,向量库选型要和检索链路一起评估。一个方案即使单独 recall 很高,如果难以接入 BM25、数据目录、权限服务和引用校验,也未必适合企业平台。反过来,一个轻量方案只要能稳定支撑混合检索、metadata filter、版本化和回滚,早期就足够使用。
18.4 元数据过滤与多租户权限¶
向量库中的 metadata 是企业检索的安全边界之一。Qdrant 文档把 filtering 放在向量搜索概念里,Azure AI Search 支持向量搜索和过滤组合,这说明企业搜索需要把“相似度最近”和“是否允许看到”一起处理。同一个 query 在不同用户、部门、租户、时间点下应返回不同候选。metadata 设计可以扩展,但表18-4 里的最小字段集合不能缺少租户、权限、来源、版本和索引治理信息;否则向量库很快会变成无法审计的共享缓存。
表18-4:metadata 字段设计。来源:本书整理。
| 字段 | 用途 | 示例 |
|---|---|---|
tenant_id |
租户隔离 | tenant-a |
acl |
角色或部门权限 | finance_manager |
source_type |
文档、字段、工单、图片 | policy |
source_version |
文档版本 | v3 |
effective_at |
生效时间过滤 | 2026-01-01 |
index_version |
索引治理 | kb-hr-v7 |
权限过滤有三种常见策略。Pre-filter 在向量搜索前过滤候选集合,安全性强,但过滤太窄可能影响 ANN 召回。Post-filter 在检索后过滤,召回稳定,但可能让模型或服务看到无权候选。Hybrid filter 把租户、密级等硬边界前置,把状态、时间等软条件后置。高风险场景应优先 pre-filter,宁可召回少一些,也不要泄露候选。这里要看候选何时被系统看见。post-filter 如果只在返回给 LLM 前执行,应用层也许看不到无权内容,但检索服务、重排服务、trace、错误日志和离线评测样本可能已经接触过这些候选。金融、法务、人力和跨租户场景中,硬边界应进入检索条件本身,至少要保证无权向量不会进入后续排序和日志。对状态、时间、标签这类软条件,可以根据召回质量做 hybrid filter,但要记录每次查询实际使用了哪些过滤字段,避免排障时只看到一个 top-k 结果。
过滤策略还会改变产品体验。权限过滤后候选为空时,系统不能简单回答“没有找到相关内容”,因为真实含义可能是“当前权限下没有可见证据”。对于 DataAgent,这两种提示会引导用户采取完全不同的动作:前者让用户换问法,后者让用户申请权限或切换数据域。向量库返回的结果里应包含过滤命中、被过滤计数和空结果原因,前端和 Runtime 才能给出正确恢复路径。图 18-4 中 pre-filter、post-filter 和 hybrid filter 的差异,最好让安全和平台团队一起确认:哪些边界必须在检索前生效,哪些条件可以在召回后参与排序和过滤。
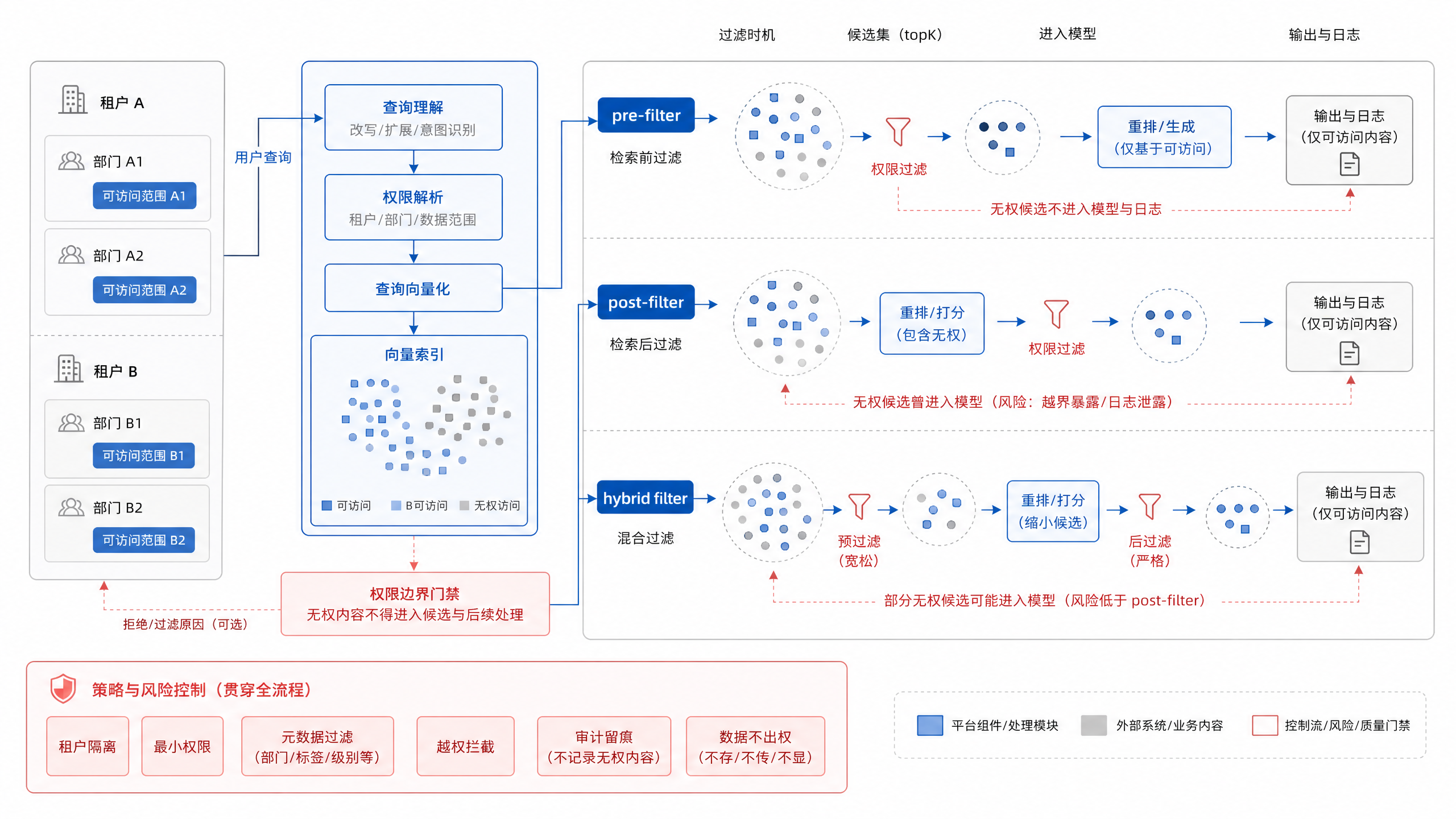
图18-4:metadata filter 与多租户权限边界。来源:本书自绘。Alt text:检索请求带租户与权限标签进入向量库,过滤条件在 ANN 搜索阶段一同生效(而非先召回后过滤),箭头标出无权数据在检索时即被排除。
18.5 索引生命周期治理¶
索引生命周期比建库更重要。Embedding 模型升级、chunk 策略变化、文档解析修复、权限字段变化、索引参数调整,都会让索引需要重建。平台要把索引当成版本化资产,不能当成一次性缓存。索引生命周期需要按表18-5 拆成阶段管理,这样“重建索引”才会从一次性运维动作变成可评估、可灰度、可回滚的发布流程。
表18-5:索引生命周期阶段。来源:本书整理。
| 阶段 | 关键动作 | 质量门禁 |
|---|---|---|
| 构建 | 编码文档、写入向量、写入 metadata、记录 lineage | 维度、metric、model version 一致 |
| 离线评测 | 用 query 集测 recall、MRR、filter hit、latency | 不低于 baseline,失败样例可解释 |
| 双写灰度 | 新旧索引同时接收更新,shadow query 对比 | 候选差异、权限差异可追踪 |
| 切流 | 小流量到全量逐步切换 | p95、错误率、引用命中率稳定 |
| 回滚 | 保留旧索引和旧模型服务 | 回滚命令和数据快照可用 |
| 归档 | 下线旧索引,保留审计信息 | 查询日志和版本元数据可追溯 |
向量库 benchmark 不能只测查询延迟。构建时间、双写成本、切流风险和回滚窗口同样是企业选型指标。索引治理还要处理“数据已经变了,索引还没变”的灰区。权限字段变更后,旧索引里的 chunk 可能仍带着旧 ACL;文档解析器修复表格错误后,旧 chunk 仍然保留错误行列;embedding 模型升级后,相同 query 在新旧索引上的候选排序可能不同。生产系统不能把这些变化都解释成用户问题或模型波动,而要把 source hash、parser version、chunk strategy、embedding model、index parameter 和 ACL schema 写进索引版本。这样出现问题时,团队才能回答是文档源变了、解析变了、向量变了,还是过滤条件变了。生命周期治理还要给“部分重建”留接口。企业知识库很少能停机全量重建:某个部门上传新制度、某个合同模板修订、某个字段权限变化,都只影响一部分 source。平台应支持按 source、tenant、collection 或 index_version 局部重建,并在双写期间比较新旧候选差异。没有局部重建能力,团队要么长期容忍旧索引,要么频繁做高风险全量切换。
局部重建还要和删除语义配合。用户删除一份文档,不代表只从对象存储里删文件;对应 chunk、向量、倒排索引、reranker 缓存、评测样本和报告引用都可能继续存在。权限撤回也是同样问题:业务系统里角色已经变化,旧向量仍带着旧 ACL,就会在检索时制造灰区。向量库接口需要把 delete_by_source、delete_by_acl 和 rebuild_by_source 做成平台能力,不能让每个应用自己清理。mini-platform 的 infra/vectorstore/ 目前保留最小接口骨架:upsert(chunks, embeddings, metadata)、search(query_embedding, filters, top_k)、delete_by_source(source_id)、build_index(index_version)、evaluate(index_version, query_set)。先把接口稳定下来,再适配 pgvector、Qdrant 或 Milvus。
18.6 工程实践:嵌入模型微调 + 向量库 benchmark¶
Ch17 讨论微调和重排,本章把它和向量库放进同一个 benchmark。企业需要评估的是组合效果:某个 embedding 模型配某个索引类型,在某个 metadata filter 下,能否以可接受成本召回正确证据。
experiment: vectorstore_benchmark
query_set: data/eval/enterprise_queries.jsonl
models:
- name: bge-m3-baseline
- name: bge-m3-finetuned
stores:
- provider: pgvector
index: hnsw
- provider: qdrant
index: hnsw
metrics:
quality: [recall@10, mrr@10, ndcg@10]
system: [p50_latency_ms, p95_latency_ms, qps, index_size_mb]
governance: [filter_hit_rate, acl_violation_count, rebuild_time_min]
图 18-5 中的向量库 benchmark 报告也要沿用这个思路:质量指标、系统指标和治理指标要放在同一页。企业选型需要同时看 recall,也要看延迟、过滤、重建和回滚。
benchmark 还要覆盖写入和更新路径。很多向量库在静态数据集上表现很好,一旦遇到高频增量写入、批量删除、权限字段更新和低峰重建,延迟和召回都会变化。企业选型时应把“白天读、夜间重建、实时写入、紧急删除”这类运行节奏放进测试脚本。否则上线后才发现索引构建占满资源,RAG 查询在业务高峰期抖动,运维团队只能临时扩容。
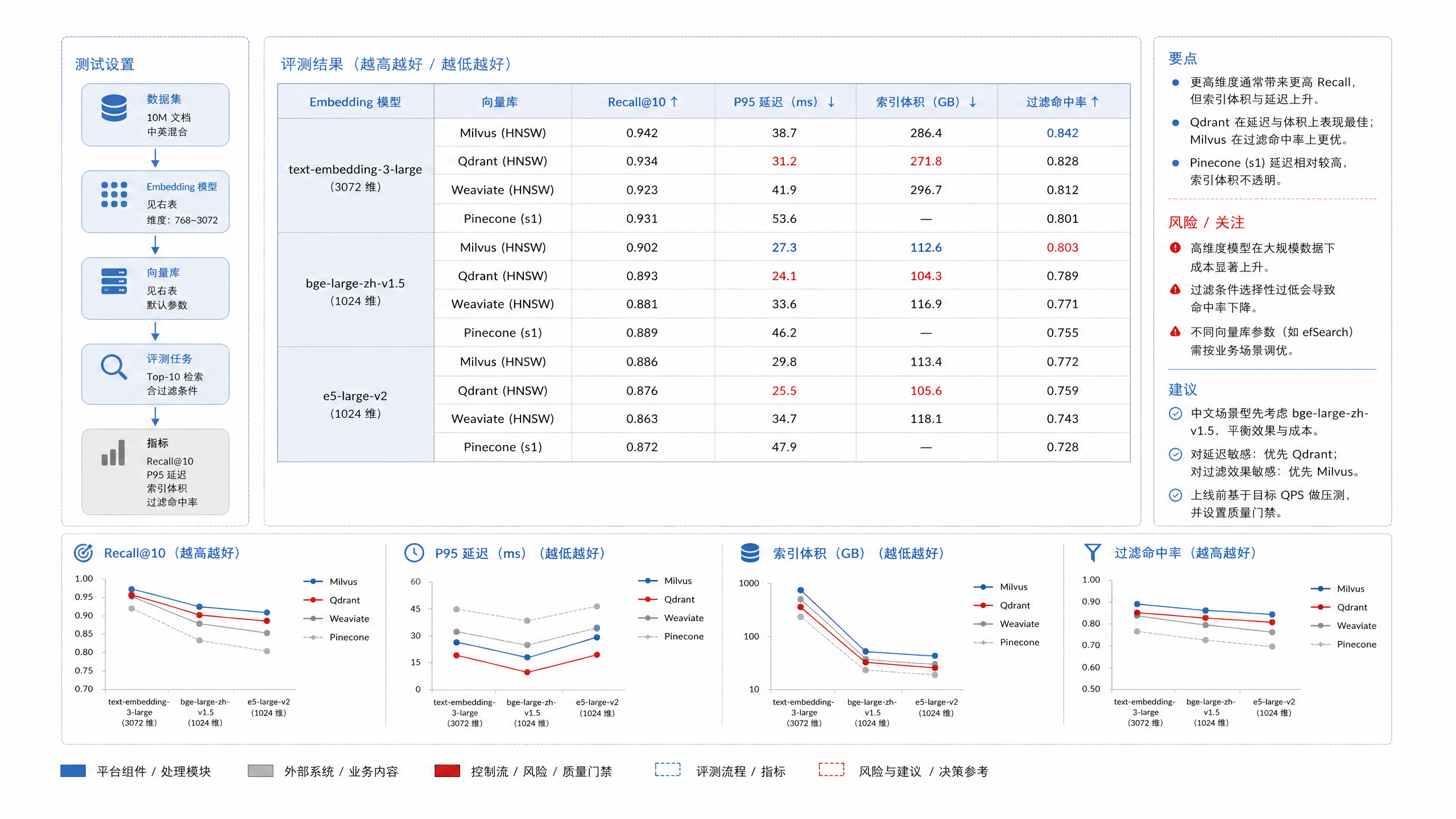
图18-5:向量库 benchmark 报告总览。来源:本书自绘。Alt text:报告页对比多个向量库在召回率、P95 延迟、写入吞吐、内存占用上的指标曲线,并标注不同索引参数下的取舍点。
18.7 向量检索的运行回放¶
向量库上线后,平台要能回放一次检索为什么返回这些候选。回放材料至少包括 query 文本、embedding 模型版本、索引版本、过滤条件、top-k、reranker 版本和最终被引用的 chunk。若只保存最终答案,团队无法判断错误来自向量召回、元数据过滤、重排还是回答生成。多租户过滤尤其要进入回放。企业检索常见事故应按召回了用户无权访问的候选,随后在日志、prompt 或调试界面泄露理解,不能停留在完全查不到。向量库应把权限过滤作为查询条件的一部分记录下来,而非在结果返回后由应用层临时删除。这样第38章的 Trace 才能证明无权内容没有进入模型上下文。
回放记录还要保留“被过滤掉的计数”,不能只保存最终候选。比如一次查询在权限过滤前有 80 个候选,过滤后只剩 3 个,用户看到的答案质量差,根因可能是权限过窄、metadata 写错,或者文档没有入库。没有过滤前后的数量和原因,团队会误以为 embedding 模型召回差。对 DataAgent 来说,这个差异会影响澄清策略:系统应该提示“当前权限下证据不足”,避免生成一个看似完整的答案。索引重建也要留版本。文档切分、embedding 模型、维度、归一化策略和元数据 schema 任一变化,都会改变召回结果。生产环境应支持新旧索引并行一段时间,用同一组 query 比较召回差异,再决定切流。否则一次看似普通的重建,可能让 RAG 和 DataAgent 同时出现质量波动。
版本迁移期间还要处理写入一致性。用户在灰度窗口上传新文档,旧索引和新索引是否都写入;某份文档在灰度期间被撤回,两个索引是否都删除;评测用的是哪个索引版本,线上回答又用了哪个版本。这些问题不写清楚,灰度就会变成“随机命中新旧数据”。较稳妥的做法是用组合版本记录 embedding、chunk、parser、metadata schema 和索引参数,并把写入、查询和评测都绑定到组合版本。
18.8 索引选型的生产判断¶
向量索引选型不能只看 benchmark 排名。企业场景更关心索引能否在数据持续更新、权限过滤、多租户隔离和低峰重建中保持稳定。HNSW、IVF、DiskANN 等索引路线各有适用条件,但最终要落到数据规模、更新频率、过滤复杂度、召回要求和运维能力。一个在公开数据集上召回率很高的索引,如果无法支持高频增量更新,放到企业知识库里可能反而不合适。
评估索引时要把过滤条件纳入测试。企业检索通常先受租户、部门、权限、文档类型、时间范围和业务域约束,然后才在可见候选中比较相似度。若索引库对元数据过滤支持较弱,就会出现两种坏结果:先过滤再检索导致召回不足,先检索再过滤导致结果被权限过滤清空。测试时应使用真实权限分布和文档分布,而非只用平均查询。索引生命周期也影响选型。增量写入、批量删除、重建、压缩、冷热分层和备份恢复都要提前验证。尤其是删除,不能只从业务库删除文档,还要处理向量索引、倒排索引、缓存和摘要。向量库是 RAG 链路的一部分,不是独立存储产品。索引选型如果没有和第20章的证据链、第27章的 Memory、以及第38章的 Trace 连接,后续很难解释一次检索为什么返回这些内容。
18.9 向量检索的质量回放¶
向量检索质量不能只通过人工感觉判断。一次检索结果应该能回放查询文本、query rewrite、embedding 模型版本、索引版本、过滤条件、召回候选、rerank 分数和最终进入上下文的片段。若回答错误,团队需要知道是文档没有入库、chunk 切分不当、向量召回漏掉、rerank 排错,还是上下文组装时被截断。没有这些中间证据,RAG 调优就会退化成反复改切分长度和 top_k。质量回放还要服务版本比较。更换 embedding 模型、调整 chunk 策略或重建索引后,同一批查询的召回集合会变化。平台应当比较旧版本和新版本的命中文档、片段位置、证据覆盖率和回答质量,而非只看平均相似度。对高风险知识库,还要抽查被新版本排除的旧证据,判断它们是噪声还是被错误丢弃。
这一节的重点是把向量数据库从“黑盒检索组件”变成“可诊断的知识基础设施”。Agent 平台依赖它提供事实证据,用户也会基于这些证据做业务判断。只要检索证据不可回放,后续生成层再稳,也无法建立可信回答。质量回放也能减少无效调参。没有回放时,团队遇到错误回答往往先改 prompt、加 top-k 或换模型;有了回放后,可能会发现正确文档根本没有入库,或者进入了候选但被权限过滤,或者进入上下文前被摘要阶段截断。不同根因对应不同修复动作。把这些证据固定下来,RAG 调优才会从经验尝试变成工程诊断。
18.10 向量库的容量与成本治理¶
向量库上线后,容量增长通常比团队预期更快。文档版本、切分副本、多模型 embedding、多租户索引、评测样本和缓存都会占用存储。若没有治理,团队会在召回质量下降或成本突然升高时才开始清理。更稳妥的方式是从一开始就记录每个向量的来源、版本、租户、业务域、过期策略和引用状态。成本治理不能简单删除低频文档。低频文档可能是关键合规证据,也可能只在事故复盘时使用。平台应把内容分成热知识、温知识和冷证据:热知识进入在线索引,温知识可以降低副本或使用较慢索引,冷证据保留原文和元数据,在需要时再进入检索链路。这样既能控制成本,也不会破坏证据完整性。向量库治理还要和文档生命周期连接。文档撤回、权限变化、合同到期、政策替换时,索引也要同步更新。只更新业务库而忘记向量索引,是 RAG 系统常见的安全和质量风险。向量库在平台里应按数据基础设施治理,发布、回滚、审计和删除都要有明确接口,不能被当作应用侧附属缓存。
容量治理最终也会影响召回质量。为了省成本盲目压缩向量、合并索引或降低副本,可能让低频但关键的文档更难被召回。平台应把成本调整纳入回归评测,确认压缩前后关键问题仍能命中证据。这样成本优化才不会悄悄牺牲可信回答。成本治理还要给业务一个可解释的选择。高频知识库可以使用更高副本、更快索引和 reranker;低频归档证据可以保留原文、metadata 和冷索引,在需要时再进入在线检索;临时项目知识可以设置过期时间,到期后转入归档或删除。平台需要把成本、响应速度和证据完整性变成可讨论的策略,并把每次策略调整纳入评测和发布记录。因此,向量库的运维指标不应只看存储和 QPS,还要看索引版本、召回覆盖、删除延迟和权限过滤后的空结果比例。这些指标能更早暴露知识基础设施的问题。
18.11 索引发布与删除一致性¶
向量索引的发布不应被视为后台运维动作。它会改变 RAG、DataAgent、Memory 和知识助手看到的候选证据,也会改变评测样本的命中路径。一个成熟的发布流程至少要记录四类版本:文档解析版本、chunk 策略版本、embedding 模型版本和索引参数版本。只有这些版本被组合起来,团队才能解释一次召回变化到底来自文档、切分、向量表示,还是索引搜索策略。
发布前要准备固定的回放集。回放集不只包含高频问答,还要包含长尾实体、权限边界、旧制度、新制度、同名指标、相似合同条款和已知失败样例。新索引构建完成后,平台应同时运行旧索引和新索引,对比候选文档、候选顺序、过滤前后数量、引用覆盖率和 p95 延迟。差异不一定代表新版本错误,但差异必须能解释。比如新索引召回了更新版本的制度,旧索引召回了历史制度,这是预期变化;如果新索引把某个受限部门的材料排到前列,就要检查 ACL schema、过滤时机和日志脱敏。
删除一致性比发布更容易被忽视。用户撤回文档、合同到期、员工离职、权限角色变更或租户删除数据时,平台必须同时处理原文、chunk、向量、关键词索引、reranker 缓存、评测样本和报告引用。只删除对象存储里的 PDF,旧向量仍可能在检索中出现;只删除向量,旧摘要或旧评测样本仍可能影响后续回答。删除接口应支持按 source、tenant、ACL、index_version 和 retention policy 执行,并在 Trace 中留下删除事件。这样安全审计才能确认敏感材料已经退出在线检索链路。
回滚也要有业务语义。旧索引保留一段时间用于事故恢复,但旧索引可能包含旧权限、旧制度或旧解析错误。平台回滚时不能只切回旧 collection,还要确认旧版本是否仍满足当前权限和合规要求。若回滚会恢复已撤回材料,系统应允许局部回滚:保留旧索引参数和旧 embedding 服务,但应用最新 ACL 与删除清单。这个能力比单纯保留一份快照更难实现,却能避免“为恢复质量而恢复风险”的问题。
对早期平台来说,索引发布可以从较小的治理面开始:每次构建生成发布记录,每次切流绑定回放报告,每次删除生成可审计事件,每次回滚记录影响范围。只要这四类记录稳定存在,后续再接入更复杂的向量库、分片策略和冷热分层,平台仍然能保持证据可解释。
18.12 检索事故的归因分层¶
向量库事故复盘要先分层归因。第一层看知识是否存在:文档是否入库、解析是否成功、chunk 是否保留关键结构。第二层看可见性:租户、部门、密级、时间范围和文档状态是否把候选正确纳入或排除。第三层看召回与排序:embedding、索引参数、hybrid 检索和 reranker 是否把正确片段推到可用位置。第四层看上下文组装:最终给模型的片段是否包含关键条件,是否被低价值材料挤出窗口。第五层才看生成:模型是否忠实使用了证据。
这种分层能避免把所有问题都推给向量模型。用户投诉引用了旧制度,根因可能是文档生命周期;DataAgent 漏掉字段定义,可能是 chunk 切分或 metadata 错误;普通员工看到无权材料,可能是过滤时机和日志脱敏问题。每次事故都应留下分层标签和修复动作,后续评测集按这些标签组织。这样下一次重建索引、调整 chunk 或更换 reranker 时,团队可以看到具体失败类型是否减少,而不是只看平均 recall。
18.13 知识入库后的质量复盘¶
知识入库完成后,平台还要复盘解析质量、引用质量和权限质量。很多知识库问题不会在导入当天暴露,而是在用户提出具体问题时出现:段落被切断,表格标题和表体分离,OCR 把金额或日期识别错,扫描件页码丢失,附件版本混在一起,或者无权文档进入候选结果。若复盘只看“导入成功多少文件”,知识工程会停在搬运阶段,无法支撑 RAG、Agent 和 DataAgent 的证据链。
复盘材料应从失败问答和人工修正中收集。用户指出引用不对、人工改选文档、回答缺少页码、审批人要求补来源、RAG 生成了无法追溯的结论,这些都应回到知识库治理。每个样本要记录文档版本、解析器版本、chunk id、页码、标题层级、表格结构、权限标签和修复动作。这样团队才能判断问题来自 OCR、版面解析、chunk 策略、metadata、权限过滤,还是业务文档本身缺少结构。
知识工程还要有发布节奏。新文档类型、新 OCR 模型、新 chunk 规则、新权限字段进入生产前,应先用一组代表性文档回放:制度 PDF、扫描合同、财务表格、图片型报告、邮件附件和多版本文档。回放通过后,再逐步扩大到更多知识域。这样第18章的知识库治理才能和第16章 embedding、第20章 RAG、第38章 Trace、第39章 Eval 连接起来。知识库承担后续智能链路的证据来源,需要保持可引用、可解释、可修复。
18.14 知识库目录与责任分工¶
知识库治理需要目录。目录记录每个知识域的 owner、文档来源、更新频率、解析策略、权限标签、引用格式、质量样本和下线条件。没有目录时,知识库会变成不断堆积的文件集合,RAG 和 Agent 只能从结果里猜测材料是否可信。目录不必一开始很复杂,但要能回答三个问题:这份知识由谁负责,什么时候更新,出了引用问题找谁修。
责任分工也要写清。业务团队负责材料真实性和更新节奏,数据或知识工程团队负责解析、chunk、metadata 和索引,安全团队负责权限标签和外发边界,平台团队负责检索、引用、Trace 和评测回流。若这些责任混在一起,常见结果是文档有人上传、没人维护,检索有人使用、没人解释,错误有人发现、没人修复。
知识库目录还要支持下线。过期制度、旧合同模板、废弃产品手册、已替换的流程说明,都不应长期留在在线索引里。下线时要检查历史报告和 Trace 是否仍需引用,必要时保留静态归档,同时阻止新 Agent 继续使用。这样知识库既能沉淀经验,也能避免过期资料污染后续回答。
18.15 向量库变更的灰度窗口¶
向量库变更需要灰度窗口。索引算法、embedding 版本、分片策略、metadata 字段、过滤顺序和混合检索权重都会改变候选集合。变更看起来只是基础设施调整,用户感受到的却是“资料找不准”或“引用变了”。因此,灰度时要同时保留旧索引和新索引,对同一批 query 比较候选、分数、过滤结果、进入上下文的片段和最终引用。
灰度窗口还要保护权限。新索引可能正确召回更多文档,也可能把无权限候选推到更靠前的位置,虽然最终被过滤掉,但已经暴露出策略顺序的风险。平台应记录被过滤候选和原因,特别是高分但无权限的结果。若这类结果增多,需要检查 metadata 写入、租户隔离和过滤执行位置,而不是只看最终回答是否泄漏。
早期向量库灰度可以按知识库或租户切流。先用影子查询记录差异,再让内部用户或低风险知识库进入新索引,最后扩大范围。旧索引保留到新版本稳定后再归档,并记录哪些历史 Trace 仍依赖旧索引。这样向量库变更才有回滚路径,也能让检索质量变化被解释。
18.16 索引分片与租户隔离的运行校验¶
向量库的多租户隔离不能只依赖应用层过滤。知识库规模扩大后,平台通常会按租户、知识域、权限等级、语言、文档类型或 embedding 版本做分片。分片能降低查询成本,也能减少误召回,但它会引入新的运行风险:路由选错分片、metadata 写入不完整、过滤顺序变化、索引重建漏掉某个租户、删除请求只清理了主索引却没有清理副本。这些问题在功能测试里不一定出现,生产里却会直接影响权限和引用可信度。
运行校验要同时检查召回和隔离。平台可以为每个租户准备允许样本、拒绝样本和边界样本。允许样本确认正确材料能被召回,拒绝样本确认其他租户或无权限文档不会进入候选,边界样本检查共享知识、集团制度、跨部门项目和临时授权材料。测试结果要覆盖最终答案、候选集合、过滤原因、重排结果和进入上下文的片段。若无权限文档经常出现在高分候选里,即使最终被过滤,也说明分片或 metadata 策略需要复核。
分片策略还要和删除、迁移、重建联动。租户迁移到新索引时,旧索引要有清理计划;文档删除时,主索引、缓存、reranker 样本和历史引用都要标记;embedding 模型升级时,新旧分片不能混合比较分数。对高风险知识库,重建期间可以保留只读旧索引,同时让新索引走影子查询。这样用户继续得到稳定回答,平台也能观察新索引是否改变权限命中和引用质量。
早期可以把隔离校验接入发布门禁。每次新增租户、调整分片规则、升级 embedding 或重建索引,都跑一组租户隔离样本,输出召回、过滤和上下文差异。这个门禁不会替代安全评审,但能把向量库的权限风险从“上线后看有没有泄漏”提前到“发布前看候选是否已经异常”。这才符合企业知识检索的风险边界。
18.17 检索缓存与索引版本证据¶
向量检索进入生产后,缓存会影响证据解释。用户连续追问时,系统可能复用上一轮召回结果;高频知识问答中,平台可能缓存 TopK 文档片段;报告生成时,多个段落可能共享同一组检索结果。缓存能降低延迟和成本,但如果没有索引版本、过滤条件和权限上下文,后续复盘就无法判断回答引用的是哪一版知识。
检索缓存至少要记录查询文本、改写后的检索 query、嵌入模型版本、索引版本、租户过滤、元数据过滤、TopK 结果、得分、生成时间和失效条件。若知识库重新分块、重新嵌入或删除文档,旧缓存应按版本失效;若用户权限变化,缓存也不能继续复用。对于高风险知识问答,缓存结果还应记录是否经过人工复核或报告发布。这样缓存不会把旧文档片段当作新证据继续传播。
缓存策略要和索引生命周期配合。索引灰度期间,平台可能同时存在旧索引和新索引;如果缓存没有版本标签,用户会在同一会话中看到两个索引的混合结果。删除文档时也要处理缓存,否则已删除内容仍可能被回答引用。平台应让 Retriever、Generator 和 Trace 都能看到 index_version 和 cache_source,让回答层知道当前证据来自实时检索、同会话缓存还是历史 artifact。
早期可以先对核心知识库启用检索证据记录。每次缓存命中都写入 Trace,并保留可回放的索引版本和文档引用。这样第18章的向量库治理会连接到第20章 RAG 证据链和第38章 Trace,而不是把缓存当作纯性能优化。
18.18 向量索引变更的线上灰度¶
向量索引变更会影响用户看到的证据。更换 embedding 模型、调整 chunk、改变 metadata 过滤、增加 hybrid 权重、重建索引或更新 reranker,都可能让召回候选发生变化。若平台一次性替换全量索引,线上答案变化很难解释。索引变更应像模型变更一样灰度发布,保留旧索引和新索引的对照样本。
灰度时要比较证据而不只比较答案。平台应记录旧索引召回的文档、新索引召回的文档、交集、差异、引用覆盖、权限过滤和最终回答变化。若新索引让答案更完整,但丢掉了某些高风险制度条款,不能直接发布;若新索引召回更广,却增加了无关候选,生成阶段可能更容易混淆。索引评估要同时看召回、精度、引用可用性和成本。
早期可以维护 shadow retrieval。真实请求仍使用旧索引回答,同时后台用新索引检索并记录差异。差异进入评测样本和人工抽检。等关键样本通过后,再按租户、知识域或任务类型切换。这样向量索引变更会变成可解释的发布动作,而不是一次不可回放的重建。
18.19 向量索引的线上健康信号¶
向量索引进入生产后,新增能力不能只看功能是否可用,还要看运行证据能否被不同角色复用。平台需要把召回样本、过滤命中、延迟、索引版本、删除回执和缓存命中记录成稳定字段,并和发布单、Trace、评测样本以及事故记录关联起来。这样一次线上问题发生后,团队可以沿着同一组事实判断影响范围、责任归属和修复顺序,而不是在模型日志、业务日志和人工说明之间来回拼接。
这类证据还要服务相邻章节的能力。它和第16章嵌入模型、第20章 RAG 和第21章知识工程相连:上游能力提供输入假设,下游能力使用执行结果,治理能力负责保存证据和复审结论。若这些材料没有统一编号和版本,章节里讨论的工程能力在生产中会被拆散。业务 owner 只能看到用户投诉,平台 owner 只能看到系统错误,安全或合规团队只能看到事后说明,最后很难判断问题到底来自数据、模型、工具、流程还是组织责任。
生产环境中常见的风险包括召回下降被当成模型问题、删除只影响主库、租户过滤在缓存层失效。这些问题在演示阶段不明显,因为演示通常只覆盖成功路径;上线后,用户会带来边界问题、重复请求、权限变化和长时间运行状态。平台团队应把失败样本纳入发布节奏,记录哪些样本需要阻断发布,哪些样本可以通过降级处理,哪些样本需要业务 owner 接受剩余风险。
向量库运营应同时看质量、权限和生命周期,不能只看吞吐与延迟。这份记录不需要复杂,但要包含时间、版本、owner、样本、处置动作和下次复查条件。没有这些字段,复盘会停留在口头经验;有了这些字段,平台才能把一次问题转成后续发布、评测和培训材料。
早期平台可以从少量高风险场景开始。先选择调用量高、业务影响大或涉及敏感数据的路径,要求每次变更都留下证据包,再逐步推广到普通场景。这样章节里的能力不会停留在概念层,而会成为可运行、可解释、可退回的工程系统。
18.20 索引退役前的影响扫描¶
向量索引退役前要做影响扫描。一个旧索引可能已经不再服务主路径,却仍被某些低频 Agent、评测样本、历史报告或灰度租户引用。直接删除会让问题在很晚之后才暴露。平台应先扫描调用日志、配置、缓存、评测集和文档链接,确认哪些路径仍依赖旧索引。
影响扫描还要说明替代路径。若新索引使用不同嵌入模型,召回样本要重新跑;若元数据字段改变,权限过滤样本要重新验收;若历史 artifact 需要解释旧答案,旧索引版本和构建参数应保留在审计记录中。早期可以把索引退役做成小型发布流程,保证知识检索能力可以收缩,也能解释历史结果。
本章小结¶
向量库的价值不在存放向量本身,而在于把语义候选检索做成可扩展、可治理、可回滚的平台能力。HNSW、IVF、PQ 等算法路线要和召回、成本、延迟一起评估;metadata 过滤、多租户权限、索引版本、重建和 benchmark 也要放进同一套生命周期。向量库负责候选检索,不负责 embedding 生成,也不负责最终业务判断。ANN 参数需要和 embedding 模型、维度、过滤策略、top-k、reranker 一起调优。高风险场景中,metadata filter 是权限边界的一部分,通常应优先采用 pre-filter。索引版本是生产资产。模型、chunk 策略或权限过滤方式变化时,应通过重建、双写或灰度完成迁移,而非把新旧向量混在同一个空间里。
参考文献¶
-
pgvector: https://github.com/pgvector/pgvector
-
Milvus Index Documentation: https://milvus.io/docs/index.md
-
Qdrant Filtering: https://qdrant.tech/documentation/search/filtering/
-
Weaviate Documentation: https://weaviate.io/developers/weaviate
-
Vespa Approximate Nearest Neighbor Search: https://docs.vespa.ai/en/nearest-neighbor-search.html
-
Azure AI Search Vector Search: https://learn.microsoft.com/en-us/azure/search/vector-search-overview