第4章 全书地图:平台参考架构与阅读路径¶
前三章分别讨论了 Agent 的边界、平台化的原因和 AI 原生业务系统。读到这里,概念已经不少:Runtime、Tool Registry、RAG、语义层、评估、网关、安全、组织分工。若没有一张地图,后续章节很容易变成组件堆叠,读者也很难判断一个问题应该放到哪一层解决。企业建设 Agent 平台时,最常见的混乱并非缺少名词,而是名词之间没有关系。业务负责人说“我们需要一个经营分析 Agent”,数据团队听成 NL2SQL,平台团队听成 Runtime 和工具调用,安全团队听成权限和审计,前端团队听成聊天工作台。大家都在谈 Agent,却在解决不同层的问题。没有一张共同地图,项目会在模型、数据、工具、界面和治理之间来回摆动。
本章的作用,是把前三章的概念判断收束成可使用的阅读地图。企业级 Agent 平台可分为四层:业务任务、运行能力、数据与知识底座、治理与运营底座。围绕这四层,后续章节会反复回到八个能力簇。DataAgent 贯穿全书,是因为它能同时暴露模型、数据、工具、评测、安全和前端问题。一个经营指标异常问题,几乎会穿过全书所有关键能力。这张地图也能帮助读者定位当前痛点。模型回答慢,不一定该换模型,可能是推理服务、上下文和网关策略问题;问数答不准,不一定是 NL2SQL 模型弱,可能是语义层、字段权限和评估集缺失;工具调用乱,不一定是框架问题,可能是 Registry、Policy 和 Trace 没建好;前端像聊天机器人,不一定是 UI 不够漂亮,可能是任务状态、证据和业务动作没有进入交互模型。
本章讨论参考架构、能力簇、平台分层、DataAgent 主线、阅读路径和建设路线。读者不需要在这一章记住所有模块名,而要建立一种判断方式:一个平台问题发生在哪一层,依赖哪些前置能力,后续应该看哪些章节。这样后面读到模型推理、数据契约、RAG、Runtime、前端、安全或组织章节时,都能把它们放回同一条任务执行链路里。这张地图还可以作为团队评审工具。每当一个新 Agent 场景被提出,团队可以沿四层逐项询问:业务任务是否足够清楚,运行时是否支持暂停、恢复和人工确认,数据与知识是否有权限和口径,治理层是否有评估、审计和成本边界。若这些问题答不上来,项目可能仍适合试点,但不宜直接承诺生产化。地图的价值就在于把“能不能做”拆成“哪些前置条件还没满足”。
图 4-1 更接近本书的阅读坐标,而非产品架构蓝图。它把业务任务、Agent 能力、数据与知识、治理与基础设施放在同一张图里,帮助读者理解后续章节为什么按这个顺序展开。
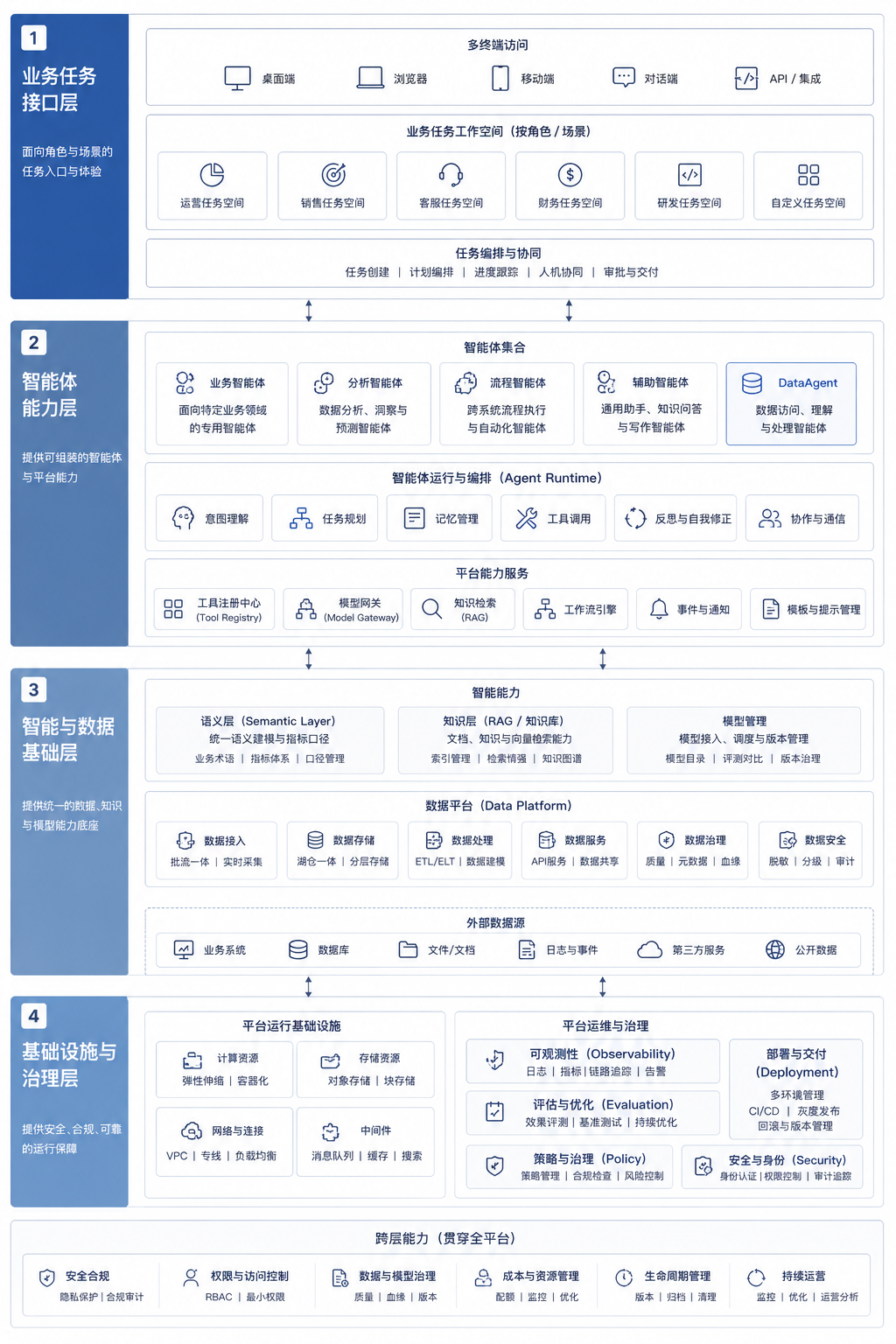
图4-1:企业级 Agent 平台四层参考架构。来源:本书自绘。Alt text:自上而下四层,业务任务层、Agent 能力层、数据与知识层、治理与基础设施层,每层标注核心职责,箭头表示上层任务依赖下层能力、下层为上层提供约束与支撑。
从业务任务层、Agent 能力层、智能与数据层,到基础设施与治理层,平台能力需要围绕任务执行链路形成整体。本章不要求读者记住所有模块名,而是建立一个阅读预期:后续章节不会按“哪个技术最热门”展开,而会按企业平台依赖关系展开。一个章节如果看似偏底层,例如模型路由、数据契约或 GPU 调度,它仍然服务于同一个目标:让 Agent 的任务执行链路可控、可复用、可评估。一个章节如果看似偏产品,例如对话 UI 或 Generative UI,也不能脱离证据、权限和运行状态单独理解。
4.1 总论地图的收束作用¶
前三章分别回答了三个问题:什么是 Agent,为什么企业会走向平台化,什么是 AI 原生业务系统。到这里,读者已经能判断一个系统是否属于 Agent,也能理解平台、框架和 AI 原生系统的区别。但如果没有一张全局地图,这些判断仍然容易散开。企业级 Agent 平台不能按单点技术理解,也不能停留在组件列表。它同时牵涉模型、数据、知识、工具、流程、前端、评估、安全、部署和组织协同。读者如果只记住“Runtime”“语义层”“评估”这些关键词,却不知道它们之间的依赖关系,后面阅读就会变成碎片化知识积累。一家多业务线企业的平台负责人需要回答“有哪些模块可以做”,也要回答更具体的问题:
- 第一个生产级 Agent 上线前,哪些底座能力必须先有?
- DataAgent 为什么不能简化为“NL2SQL + 图表”?
- Runtime、Tool Registry、审批、trace、评估之间是什么关系?
- 为什么本书先讲模型、数据、知识,再讲 Agent 能力和业务系统?
- 不同读者应该顺序读完,还是按角色跳读?
第四章把前三章的概念判断压缩成一张可执行的阅读地图。它不复述目录,而是说明后面每一章在整个平台中处于什么位置、解决哪类问题、和哪些章节存在前后依赖。
4.2 四层参考架构:从业务任务到治理底座¶
企业级 Agent 平台常见的画法问题,是一上来就罗列太多组件。总论更适合先用四层理解全局。第一层是业务任务层。这里是用户感知价值的地方:DataAgent、报价 Agent、工单 Agent、经营分析工作台、销售任务工作台,以及后续各种 AI 原生业务系统。它回答“企业用 Agent 完成什么任务”。第二层是 Agent 能力层。这里决定 Agent 如何被组织和运行:任务状态、工具调用、规划策略、长任务、人工介入、多 Agent 协作、协议与框架选型。它回答“Agent 如何把任务推进下去”。
第三层是智能与数据层。这里为 Agent 提供能力原料:模型推理、结构化输出、RAG、知识工程、语义层、湖仓、OLAP、元数据、血缘、指标口径。它回答“Agent 凭什么理解、判断和生成结果”。第四层是基础设施与治理层。这里保证系统能长期运行:模型部署、网关、多租户、可观测性、评估、成本、限流、降级、安全、合规和组织机制。它回答“Agent 如何被稳定、可信、可控地运行”。
表4-1:四层参考架构各层的核心问题与对应章节。来源:本书整理。
| 层级 | 核心问题 | 主要对应章节 |
|---|---|---|
| 业务任务层 | 用 Agent 完成什么业务任务 | Part VI, Part XI |
| Agent 能力层 | Agent 如何规划、调用工具、执行长任务 | Part V |
| 智能与数据层 | Agent 使用什么模型、数据和知识 | Part II, III, IV |
| 基础设施与治理层 | 系统如何部署、观测、评估、安全运行 | Part VII, VIII, IX, X |
四层结构的作用,是帮助读者把问题放回正确位置。没有这张层次图,企业很容易发生两种误判:把所有问题都下沉成模型问题,或者把所有问题都抬高成业务问题。明明是语义层缺失、工具契约混乱、审批边界不清,却被归咎于“模型不够强”;明明是 trace 不统一、评估样本缺失、运行状态不可恢复,却被说成“业务场景太复杂”。四层架构提供的,正是定位这两类问题的共同语言。
四层之间还有依赖顺序。业务任务层提出目标,但不能绕过运行能力直接调用模型;Agent 能力层推进任务,但必须从数据与知识层拿到可信上下文;数据与知识层提供证据,但要接受基础设施与治理层的权限、审计和成本约束。把依赖顺序讲清后,平台建设才不会变成并行堆功能。比如前端工作台可以先做原型,但没有 trace 和审批事件,它就无法承担高风险动作;DataAgent 可以先做 NL2SQL,但没有语义层和权限,它就不能直接面向多部门开放。
4.3 八个能力簇:平台骨架、智能放大与反馈系统¶
在四层之中,构成 Agent 平台骨架的,是一组会反复出现在后续章节里的能力簇。本书把它们收束成八个。这八个能力簇各自回答不同问题。Runtime 处理任务如何被创建、推进、暂停、恢复和终止;Registry 处理工具、Agent、能力和版本如何统一管理;Planner 处理系统如何决定下一步,避免停留在文本生成;Memory 处理会话状态、长期偏好和任务上下文如何延续;RAG / Knowledge 处理文档、元数据和知识上下文如何进入 Agent;Observability 处理 trace、日志、指标和会话回放如何统一记录;Eval 处理如何判断版本变好还是变坏;Policy 处理权限、脱敏、审批和安全边界如何被执行。这八个能力簇不能当成功能清单。它们对应企业平台需要长期维护的三类能力。
没有 Runtime,系统只能演示,不能可靠执行。没有 Registry,工具会越来越多、越来越乱。没有 Planner,模型会在错误路径上自由发挥。没有 Memory,长任务和多轮任务会迅速失真。没有 RAG 和知识工程,系统难以连接企业上下文。没有 Observability,出错后无法解释。没有 Eval,版本好坏只能靠感觉。没有 Policy,越权、泄漏和绕过审批迟早出现。也可以换一种方式理解这八个能力簇:Runtime、Registry 和 Policy 构成执行骨架,让 Agent 能被统一运行和约束;Planner、Memory 和 RAG / Knowledge 构成智能放大器,让 Agent 能理解上下文并动态推进;Observability 和 Eval 构成反馈系统,让平台避免黑箱化和失控。后面章节虽然会展开很多具体技术,但这组三分法可以作为定位工具:当前主题到底是在补执行骨架、智能放大器,还是反馈系统?Runtime、Registry、Planner、Memory、RAG / Knowledge、Observability、Eval 与 Policy 分别承担执行骨架、智能放大器和反馈系统的职责。
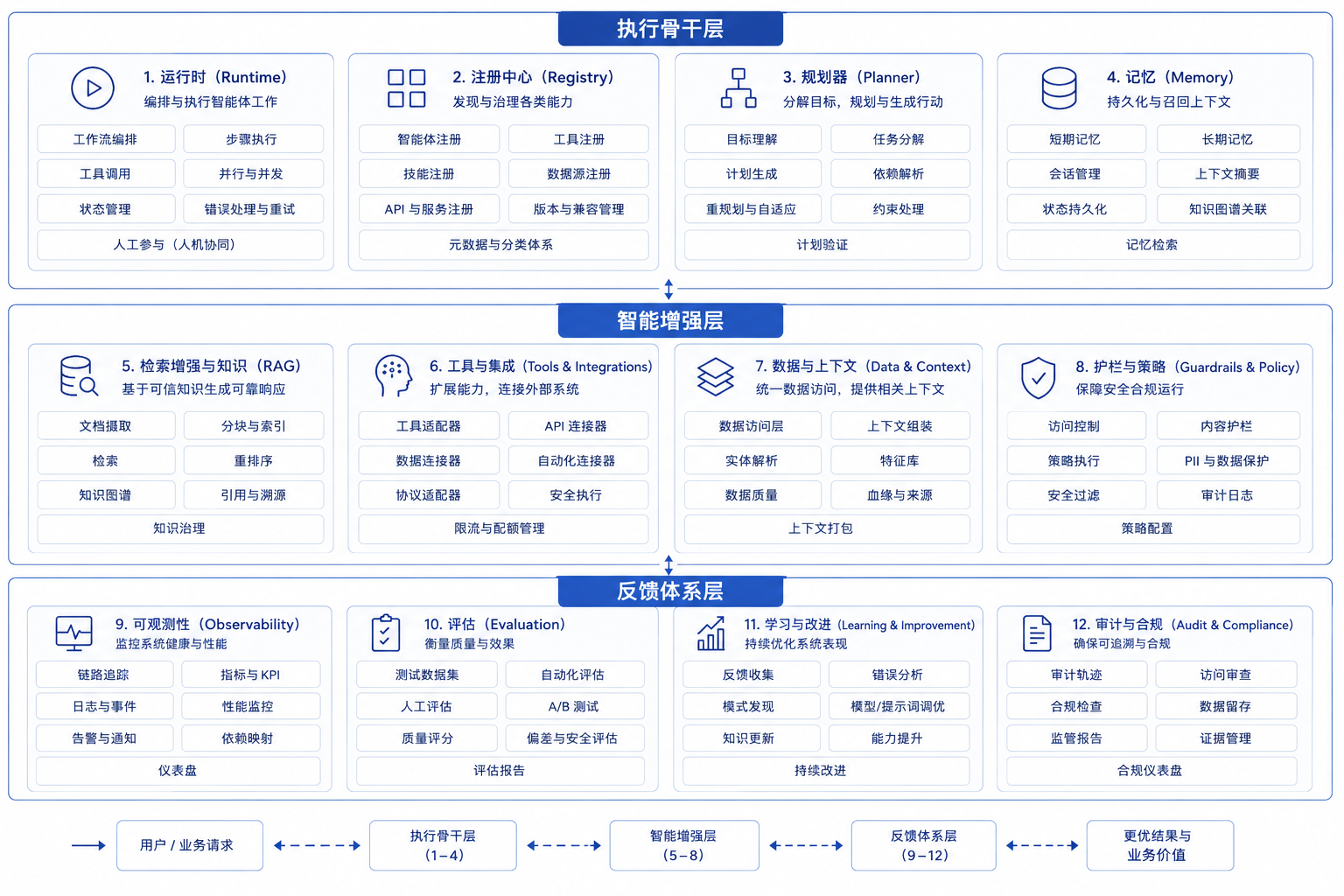
图4-2:企业级 Agent 平台八个能力簇。来源:本书自绘。Alt text:八个能力簇分为执行骨架(Runtime、Registry、Policy)、智能放大器(Planner、Memory、RAG/Knowledge)和反馈系统(Observability、Eval)三组,连线表示各簇之间的调用与反馈关系。
4.4 DataAgent 主线:让全栈能力显影¶
本书不只讲 DataAgent,却把 DataAgent 作为主线场景。原因不在于问数最热门,而在于 DataAgent 几乎天然穿过企业级 Agent 平台的主要层级。一个看似简单的问题,例如“上周华东区毛利率异常的原因是什么”,背后会同时触发多个系统问题:
表4-2:DataAgent 为何在每一架构层都绕不过去。来源:本书整理。
| 层级 | DataAgent 为什么绕不过去 |
|---|---|
| 模型层 | 需要理解问题、规划路径、生成 SQL、解释结果 |
| 数据层 | 需要语义层、指标口径、湖仓、OLAP 和数据质量 |
| 知识层 | 需要元数据、历史分析、业务术语、制度和案例 |
| Agent 层 | 需要 Runtime、工具调用、Planner、状态管理和人工介入 |
| 治理层 | 需要权限控制、trace、评估、成本和审计 |
| 前端层 | 需要图表、表格、引用、报告和任务工作台 |
DataAgent 适合作为主线场景。它不是唯一重要的业务场景,却能把企业级 Agent 平台的主要层级都暴露出来。把这个任务拆开看,一家多业务线企业的一次 DataAgent 请求至少要经过七个检查点。任务创建阶段要确认用户身份、租户和问题范围;上下文加载阶段要拿到指标口径、历史分析和可访问数据;路径规划阶段要决定先查什么、后查什么、是否需要跨多个工具;工具执行阶段要约束 SQL、API、Python 等动作;结果解释阶段要区分事实、推断和建议;治理记录阶段要留下 trace、成本、审批和风险证据;结果交付阶段要给出图表、引用、结论和后续动作。如果把 DataAgent 误解成“自然语言转 SQL”,平台建设从第一天就会跑偏。它同时连接数据智能、Agent 执行、AI 原生工作台和企业治理。因此,Part VI 在全书中承担主线地位。它把前面的模型、数据、知识、Agent 能力,以及后面的评估、安全、前端拉到同一个综合场景中,不能把它当成一个孤立案例。一个经营指标异常问题会同时穿过任务运行时、语义层、元数据、RAG、Planner、模型网关、SQL / Python 工具、trace、评估和结果交付。
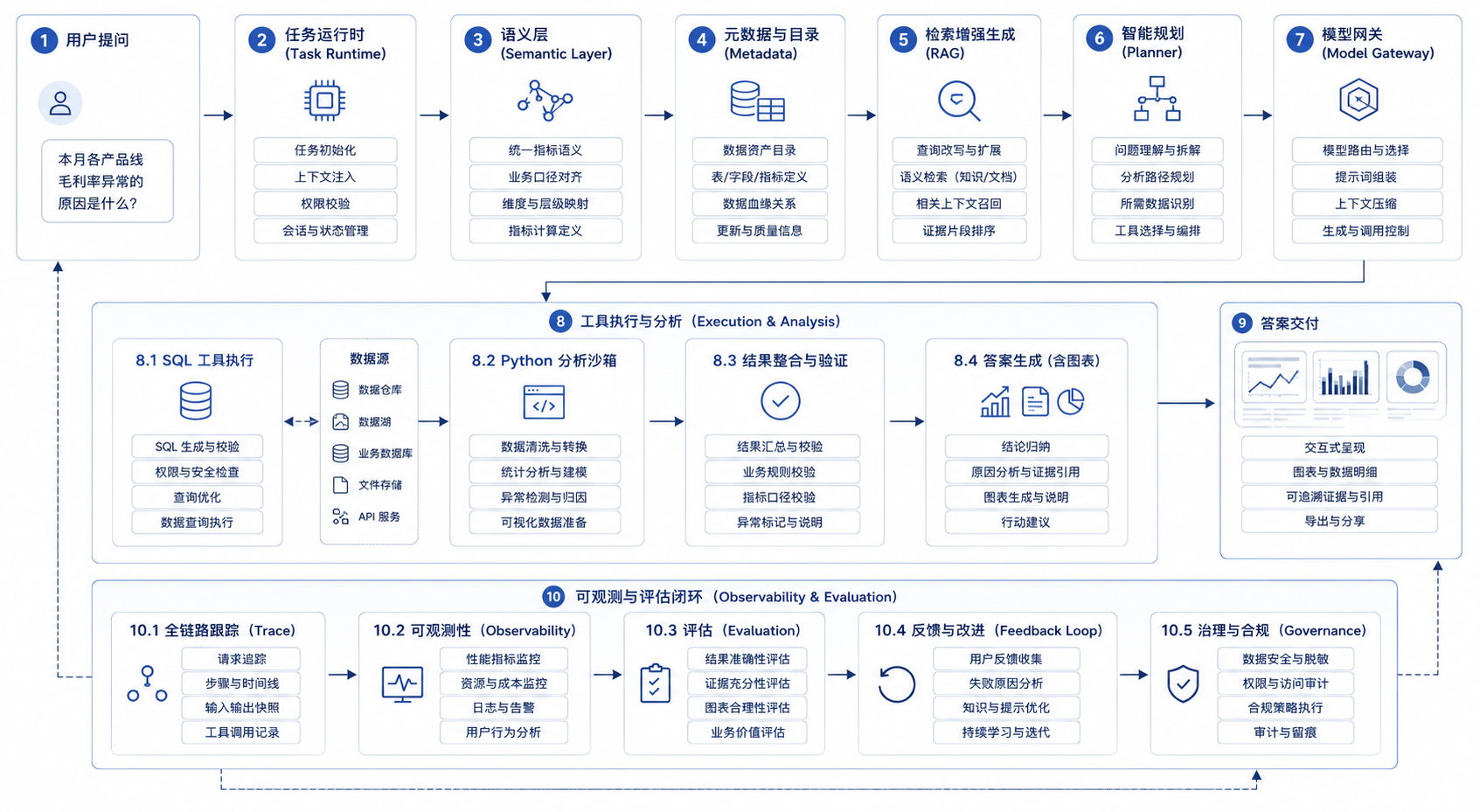
图4-3:DataAgent 端到端任务链路。来源:本书自绘。Alt text:一条从用户提问出发的横向链路,依次经过意图理解、语义层编译、SQL 生成与执行、结果解释与可视化,每个环节标出所依赖的平台能力簇,末端汇出带证据的业务结论。
4.5 全书组织顺序:按平台依赖关系展开¶
很多 Agent 书会从聊天界面、提示词或工具调用开始讲。这种顺序容易上手,但一旦进入企业落地,就会遇到一个问题:前端体验跑得很快,底层语义、评估、权限、运行时和审计却都没有准备好。本书的组织顺序,按企业级平台逐步形成的依赖关系安排。先讲模型与推理,因为没有基础推理、结构化输出、模型路由和推理优化,后面的 Agent 决策无从谈起。再讲数据基础设施和知识工程,因为企业 Agent 的差异,往往不来自模型本身,而来自它能否安全地连接正确数据、正确口径和正确知识。接着进入 Agent 基础能力,因为有了模型、数据和知识之后,才有必要讨论 Runtime、Tool Registry、MCP、Planner、Memory、HITL、多 Agent 与框架选型。随后进入 DataAgent 主线,把前面的底座能力放进一个真实业务场景中检验。之后进入观测、评估、成本、部署、前端、安全、合规和组织。这些能力决定平台能否长期运行,避免系统停在一次演示上。
表4-3:全书各部分在依赖链中的位置及如此排序的原因。来源:本书整理。
| 书中部分 | 为什么放在这里 |
|---|---|
| Part II 模型与推理层 | 建立模型能力与结构化输出基础 |
| Part III 数据基础设施层 | 建立可访问、可信、可治理的数据底座 |
| Part IV 向量、检索与知识工程 | 让 Agent 能连接企业非结构化知识 |
| Part V Agent 基础能力 | 建立任务执行、工具调用和协作机制 |
| Part VI DataAgent 主线深潜 | 用一个综合场景拉通全栈能力 |
| Part VII-X 生产化与治理 | 补齐观测、评估、成本、部署、安全和组织机制 |
| Part XI 案例集 | 把平台能力迁移到更多业务 Agent |
这个顺序来自工程依赖。读者可以跳读,但要保留对上下游依赖的判断。第四章除了给技术地图,还要给阅读地图。不同角色不需要用完全相同的方式读这本书。平台负责人和 CTO 可以先抓平台边界、年度路线、成本、治理和组织协同,重点看第1章、第2章、第4章以及 Part VII 到 Part X。架构师更适合把四层架构、八个能力簇和章节依赖关系读通,再进入 Runtime、Tool Registry、RAG、评估和部署章节。数据智能工程师应优先关注语义层、RAG、DataAgent、NL2SQL 和评估体系;AI 应用开发者则应从 Runtime、工具接入、任务工作台和结果交付开始。安全与合规负责人不必先读所有实现细节,但要抓住权限边界、审批、trace、评估、Guardrails 和法规控制矩阵。
团队共读 Part I 时,可以先用第1章和第2章统一概念,确认团队说的 Agent、平台、框架、Workflow 是否指同一件事;再用第3章讨论哪些业务系统值得 AI 原生化,哪些场景只需要在旧系统上增加一个对话入口;最后用第4章把这些判断映射到团队路线图。这样的共读结果更接近一套后续建设时可以反复引用的共同语言。共读之后,团队最好把现有项目标到这张地图上。哪些项目只有业务任务和前端入口,缺少运行能力;哪些项目有模型和 RAG,却没有评估和权限;哪些项目已经接入工具,但工具注册、审批和审计还散在各处。把项目放到地图上,能避免“每个团队都觉得自己在做平台”的错觉,也能帮助管理者判断哪些能力应由平台团队统一建设,哪些仍应留在业务应用里。
读者已经有实际项目时,也可以按当前痛点跳读。Agent 效果不稳定时,应优先看 Runtime、Planner、Trace 和 Eval,同时检查 prompt 是否承担了过多系统责任;问数经常答不准时,应回到语义层、Schema Linking、NL2SQL 和 DataAgent 评测;工具越来越多、风险难控时,应先看 Tool Registry、Policy、审批和成本治理;平台路线说不清时,应回到 Part I、成本、安全和组织路线;前端像聊天机器人而不像工作台时,应把第3章的 AI 原生业务系统、第47章的对话 UI 和第48章的 Generative UI 连起来看。这张阅读地图让本书更接近工作手册。读者不必只能从第一页顺序读完,也可以按问题定位章节。
4.6 一年建设路线:从首个试点到平台化复制¶
如果一家多业务线企业准备用一年时间把企业级 Agent 平台从 0 做到可服务多条业务线,比较合理的节奏是围绕真实场景逐步沉淀共性能力,避免一开始就建设“大而全平台”。表 4-4 按季度拆出技术、治理和组织三条线,用来帮助团队识别每个阶段最该沉淀的公共资产。表中的季度不是固定排期,实际项目应按业务风险、团队能力和已有基础设施调整节奏。
表4-4:一年建设路线各季度的技术、治理与组织重点。来源:本书整理。
| 阶段 | 技术重点 | 治理重点 | 组织重点 |
|---|---|---|---|
| 第一季度 | Runtime、模型入口、工具注册、基础 trace、首个试点 | 工具风险等级、最小审批准则 | 明确平台团队边界和业务试点负责人 |
| 第二季度 | 评估、成本归集、审批接入、基础管理界面 | 评测样本模板、上线准入标准 | 建立场景共创和复盘机制 |
| 第三季度 | 语义层、RAG、更多工具接入、第二业务线复制 | 统一数据口径、权限和 trace 规范 | 推动业务团队按模板接入 |
| 第四季度 | 灰度、降级、SLO、供应商接入、平台目录 | 事故复盘、版本治理、合规检查 | 建立平台运营节奏和年度路线 |
这张路线图的重点不在季度数字,而在顺序:先把执行链路站稳,再做规模化和组织化。每个阶段都应该沉淀一种可复用的公共资产。第一季度的资产是统一任务状态模型和工具风险等级:前者决定 Runtime、Trace、审批和恢复能否说同一种语言,后者决定新工具接入时是否能快速判断风险。第二季度要把评测样本模板和上线准入清单固定下来,让后续场景不再从“怎么证明可上线”重新讨论。第三季度的重点是语义层规范、数据权限规范和知识接入规范,因为复制到第二条业务线时,最大的摩擦通常来自指标口径、字段权限、文档边界和责任主体。第四季度再沉淀平台目录、复盘模板、成本与质量运营报表,把平台从项目交付转成持续运营。
这些公共资产看起来不像功能,却决定平台能不能复用。没有任务状态模型,每个 Agent 都会发明自己的“运行中”“等待审批”“失败重试”;没有评测模板,每次上线都只能靠现场演示;没有语义层和权限规范,DataAgent 一旦跨部门就会被口径和授权问题卡住;没有复盘和运营报表,平台团队只能证明自己“做了很多事”,很难证明平台质量是否变好、单位调用成本是否下降、业务线是否真正复用能力。路线图复盘时也要看这些资产有没有被第二个场景使用。第一个场景写出的工具注册规范,如果第二个场景仍然手写工具调用,说明规范没有真正成立;第一个场景沉淀的评测模板,如果第三个场景无法复用,说明样例结构过于定制。平台化的信号是后续场景接入时重复步骤减少,而不是文档数量增加。
这也是全书采用 DataAgent 主线的原因。它提供了一个可反复验证的平台样本:模型层、数据层、知识层、Agent 层、前端层和治理层都会在这个样本里暴露缺口。读者读完任何一部分,都可以回到 DataAgent 问一句:这个能力怎样让一次经营分析更可信、更可控、更容易复盘。很多平台路线图失败,原因不一定是技术目标写错,而是只写技术目标,不写治理目标和组织目标。只有技术目标,平台会建出来却用不好;只有治理目标,平台会规矩很多却缺少采纳;只有组织目标,平台会讨论很多却缺少可运行底座。三者要一起推进。
早期路线图还要克制范围。企业很容易在年度规划里同时写上模型网关、RAG、DataAgent、多 Agent、自动化审批、评估平台和安全治理,最后每一项都只有原型。更稳的做法是选择一条能贯穿全链路的主线场景,把任务状态、工具注册、权限、trace、评估和发布流程先跑通;第二条业务线再验证这些能力是否可复用。平台能力是否成立,要看第二个场景能否少做重复工作,而不只看目录是否完整。
4.7 全书主线的阅读方式¶
本章的地图不应被读成模块清单,而应被读成一条生产链路。企业 Agent 从用户任务开始,经过模型能力、数据上下文、工具动作、运行状态、评测反馈、安全合规和组织运营,最终变成可持续维护的业务系统。任何一层缺失,系统都会在试点和生产之间断开。读者可以按两种方式使用这张地图。第一种是从上往下读,先建立平台观,再逐层理解模型、数据、工具、运行时和治理能力。第二种是带着项目问题回查:如果当前项目卡在问数准确性,就重点读第33章到第39章;如果卡在工具执行和审批,就重点读第22章到第30章;如果卡在上线稳定性,就回到第38章到第52章。全书后续章节会保留这种写法:先说明场景和边界,再进入架构与工程实现,最后回到运行证据和上线判断。这样安排是为了避免读者把 Agent 平台理解成一组产品功能。真正需要建设的,是一套能把模型输出约束为企业动作、把动作连接到证据、把证据连接到责任的工程体系。
4.8 将现有项目映射到全书地图¶
很多读者不会从空白状态开始建设平台,而是已经有若干试点:一个知识问答助手、一个指标问答页面、一个审批草稿生成器、一个客服质检脚本,或者一个接了少量工具的聊天机器人。阅读本书时,最有价值的做法,是把这些项目逐一映射到四层架构和八个能力簇上,而非先给它们改名。映射时先写清楚当前项目的用户任务,再标出它依赖的模型、数据、知识、工具、运行状态、评测、安全和前端能力。写完以后,缺口往往会很直观:有些项目只有前端和 Prompt,没有 Runtime;有些项目有 RAG,却没有文档版本和权限过滤;有些项目已经能调用工具,却没有 Registry、Trace 和审批事件;有些项目做了评测,却没有把线上失败样本回流。
项目映射还可以帮助团队决定下一步投入。若多个试点都在重复接模型、写工具适配和做日志,说明平台层应优先沉淀模型网关、Tool Registry 和 Trace。若多个试点都卡在数据口径和字段权限,说明语义层、指标治理和数据访问策略应优先于更多 Agent 框架选型。若业务用户觉得结果难以相信,问题可能来自证据展示、引用、复核入口和失败解释,模型只是其中一个排查对象。映射的目的,是把分散问题整理成平台路线图,而不是给每个项目打分。这样团队不会把一个项目的局部成功误认为平台成熟,也不会因为某个试点失败就否定整条路线。
对管理者来说,这张映射表还能澄清责任。业务团队负责场景目标、验收样本和运营结果;平台团队负责可复用底座、运行证据和发布门禁;数据团队负责口径、权限和质量;安全与法务团队负责策略、审计和复核要求。一个项目如果只有业务 owner 而没有平台 owner,后续会在工具治理和运行责任上失控;如果只有平台 owner 而没有业务 owner,则容易做成没有采纳的通用能力。把现有项目放回全书地图,就是把阅读路径转成组织协作路径。后续章节可以按这个映射结果选择阅读顺序,也可以反过来修正团队的年度建设计划。
4.9 从地图到评审动作¶
全书地图最终要落到评审动作上。企业团队在讨论一个 Agent 场景时,常见问题是会议里所有人都同意“可以先试点”,但没人把试点和生产之间的差距写清楚。第1章讨论边界,第2章讨论平台,第3章讨论 AI 原生业务系统,本章则要求团队把这些判断变成一组可复查的问题。一个场景进入立项评审时,先写出用户任务链路:用户提出什么目标,系统需要读取哪些数据,可能调用哪些工具,哪些步骤会改变业务状态,结果会被谁使用。任务链路写完后,再把每一步标到四层架构里。若某一步找不到归属,说明团队还没有决定它由业务应用、平台能力、数据底座还是治理机制承担。
评审时还要区分“当前可以演示”和“后续可以运营”。一个知识助手能回答制度问题,说明模型、检索和前端入口已经具备雏形;但如果没有文档版本、权限过滤、引用证据和失败样本回流,它仍然只能算试点。一个 DataAgent 能生成 SQL,说明模型和语义提示有一定能力;但如果没有指标口径、查询资源隔离、字段权限和 SQL 回放,它还不能进入多部门生产。一个审批草稿 Agent 能写出邮件,说明生成能力可用;但如果没有审批对象、发布权限、外发审计和撤回流程,它不能替代正式业务流程。地图的用途,就是让团队把这些差距逐条写出来,避免用一次顺利演示代替生产判断。
把地图用在项目评审时,可以形成三类结论。第一类是准入结论:当前场景适合做原型、受控试点、有限生产,还是可以进入平台目录。第二类是缺口结论:缺的是语义层、Tool Registry、Runtime 状态、评估样本、HITL、Trace、安全策略,还是前端工作台。第三类是责任结论:哪些缺口由业务团队补样本,哪些由数据团队补口径,哪些由平台团队补能力,哪些由安全和合规团队定义门禁。没有这三类结论,路线图很容易只剩“继续优化模型”“继续完善平台”这类宽泛表述,后续复盘也很难判断究竟完成了什么。
一个可执行的评审会不需要很复杂,但要坚持证据优先。业务方要带来真实任务、失败样例和采纳标准;平台方要带来可复用能力和当前限制;数据方要带来指标口径、权限边界和数据质量状态;安全合规方要带来风险分级和审计要求。会议结束时,团队应能把该场景放到全书地图的一组坐标上:它依赖哪些章节能力,哪些能力已经具备,哪些能力需要在下一阶段补齐。这样阅读路径、建设路线和组织分工会合在一起。本书后续章节虽然会进入很多实现细节,但判断标准始终回到这里:一个能力是否让任务链路更清楚,是否让运行证据更完整,是否让责任边界更可执行。
4.10 读者预期与平台边界¶
这张全书地图承担预期管理作用。企业级 Agent 平台不是单点技巧的集合,而是一套建设和评审框架。刚启动试点时,团队最需要判断任务边界和平台边界;进入第二个场景时,最需要判断哪些能力可以复用,哪些仍然是业务专用实现;进入规模化时,最需要判断运行证据、成本、SLO、安全和组织责任是否跟得上。第四章把这些问题放在同一张地图上,后续章节才有共同坐标。
本书会把企业 Agent 平台的主干能力展开到可评审、可实现、可运行的程度,但不会把每一种行业场景都写成完整案例,也不会把 mini-platform 写成可直接替代商业系统的完整产品。mini-platform 的价值在于给出最小可运行路径,让读者看到 Runtime、Registry、语义层、Trace、Eval、HITL 等能力怎样接在一起;真实生产系统仍需要接入企业自己的身份、权限、数据目录、审批系统、监控系统和发布流程。
读者使用这张地图时,问题不应停在“缺哪个组件”。更有效的提问是:当前业务任务需要哪些证据才能上线,哪些动作会产生副作用,哪些数据口径会引发争议,哪些失败需要被用户看见,哪些责任需要留在人工流程中。一个项目如果能调用模型、检索文档和执行工具,只能说明功能链路初步跑通;若无法回答这些评审问题,它距离企业级平台仍然有差距。
4.11 地图驱动的建设顺序¶
全书地图可以帮助团队安排建设顺序。模型网关、工具注册、Trace、评测样本和权限边界属于早期底座;Memory、多 Agent、DataAgent、Generative UI 和多模态入口属于在底座稳定后逐步扩展的能力;安全、合规和组织治理需要从第一天介入,但可以先覆盖高风险链路。读者应把章节顺序理解为能力成熟路线,而非项目排期模板。
建设顺序要看依赖关系。没有稳定语义层,DataAgent 很难给出可复核的业务分析;没有 Trace 和 Eval,安全与合规就缺少运行证据;没有工具注册和 HITL,业务 Agent 里的高风险动作就无法解释。地图把这些依赖摆出来,团队就能判断哪类能力应先补齐,哪类能力可以在真实材料更充分时再扩展。
短板治理也要跟着地图走。若某个场景的失败来自指标口径,优先补语义层、数据目录和权限过滤;若失败来自工具误用,优先补 Registry、Runtime 状态和审批事件;若失败来自用户不信任结果,优先补引用证据、Trace、Eval 和前端解释。这样平台建设不会被局部热点牵着走,也不会因为某一类材料丰富就让路线图失衡。
4.12 地图驱动的场景准入¶
团队把第四章用于项目评审时,可以把它当成一张“缺口定位表”。每个正在做的 Agent 项目,都先写出用户任务、数据来源、工具动作、运行状态、证据记录和责任人,再放回四层架构。若某个项目找不到对应的运行状态,说明 Runtime 或 Trace 还没有接入;若某个项目找不到对应的数据口径,说明语义层和数据目录还没有准备好;若某个项目找不到对应的责任人,说明组织流程仍停在试点阶段。
场景准入可以形成三类结论。第一类是阶段结论:当前场景适合做原型、受控试点、有限生产,还是可以进入平台目录。第二类是缺口结论:缺的是语义层、Tool Registry、Runtime 状态、评估样本、HITL、Trace、安全策略,还是前端工作台。第三类是责任结论:哪些缺口由业务团队补样本,哪些由数据团队补口径,哪些由平台团队补能力,哪些由安全和合规团队定义门禁。
一个可执行的评审会不需要很复杂,但要坚持证据优先。业务方带来真实任务、失败样例和采纳标准;平台方带来可复用能力和当前限制;数据方带来指标口径、权限边界和数据质量状态;安全合规方带来风险分级和审计要求。会议结束时,团队应能把该场景放到全书地图的一组坐标上,并写清下一阶段需要补齐的能力和证据。
4.13 全书地图作为团队协作契约¶
全书地图还可以被当作团队协作契约使用。企业做 Agent 平台时,产品团队、数据团队、平台团队、安全团队和业务团队往往各自拿着一套语言:产品讲体验,数据讲指标,平台讲运行时,安全讲策略,业务讲交付。若没有共同地图,评审会很容易变成局部观点的叠加。第4章给出的四层架构和八个能力簇,可以把这些语言转成同一组问题:任务入口在哪里,数据证据从哪里来,动作由谁执行,风险如何被拦截,结果如何被评测。
协作契约要落到材料。一次 Agent 场景立项时,产品团队提供用户任务和产物样例,数据团队提供数据契约和质量状态,平台团队提供 Runtime、Registry、Trace 和 Eval 接入方式,安全团队提供权限和审批边界,业务 owner 提供验收样本和责任人。全书地图可以作为评审清单的顺序,但不应变成打勾表。每一项都要回答“如果这里失败,用户看到什么,平台如何恢复,谁负责修正”。
地图还能减少章节之间的割裂。读者读到第6章推理服务时,可以回到地图上看它怎样影响第7章优化、第8章结构化输出和第45章网关;读到第34章 NL2SQL 时,可以顺着地图追到第11章湖仓、第15章语义层、第38章 Trace 和第39章 Eval。这样全书不会像一组独立专题,而会像一套平台工程问题逐层展开。
团队可以把这张地图用于读书会或项目评审。每读完一个 part,就把正在做的项目贴回地图:哪些能力已经接入平台,哪些仍在应用侧,哪些缺少证据,哪些缺少责任人。这个动作比单纯讨论章节内容更有价值,因为它能把阅读内容转成落地对照表,也能暴露当前项目最需要补齐的工程材料。
4.14 全书阅读路径与能力取舍¶
全书地图的作用是帮助读者识别先后关系,避免把完整平台当成一次性建设目标。模型网关、工具注册、Trace、评测样本和权限边界属于早期底座;Memory、多 Agent、DataAgent、Generative UI 和多模态入口属于在底座稳定后逐步扩展的能力;安全、合规和组织治理需要从第一天介入,但可以先覆盖高风险链路。读者应把章节顺序理解为能力成熟路线,而不是项目排期模板。
阅读取舍要看业务链路。若团队主要做数据分析 Agent,应优先读数据基础设施、语义层、NL2SQL、Trace 和 Eval;若团队主要做办公自动化 Agent,应优先读工具注册、Planner、HITL、Guardrails 和前端事件模型;若团队正在做统一平台,应把部署、网关、成本和组织治理提前纳入。不同路径可以跳读,但不能跳过证据、权限、评测和恢复这四类主题。
本书后续章节会反复回到同一组问题:能力是否可复用,证据是否可追踪,失败是否可恢复,责任是否可确认,成本是否能解释。只要读者用这组问题检查每个章节,就能把具体技术点连接成平台工程,而不是把它们当成独立知识点。
4.15 全书主线的阅读节奏¶
全书地图进入生产后,新增能力不能只看功能是否可用,还要看运行证据能否被不同角色复用。平台需要把章节依赖、平台能力、工程证据、风险边界和读者角色记录成稳定字段,并和发布单、Trace、评测样本以及事故记录关联起来。这样一次线上问题发生后,团队可以沿着同一组事实判断影响范围、责任归属和修复顺序,而不是在模型日志、业务日志和人工说明之间来回拼接。
这类证据还要服务相邻章节的能力。它和各 Part 的开篇、DataAgent 主线和安全治理章节相连:上游能力提供输入假设,下游能力使用执行结果,治理能力负责保存证据和复审结论。若这些材料没有统一编号和版本,章节里讨论的工程能力在生产中会被拆散。业务 owner 只能看到用户投诉,平台 owner 只能看到系统错误,安全或合规团队只能看到事后说明,最后很难判断问题到底来自数据、模型、工具、流程还是组织责任。
生产环境中常见的风险包括读者把章节当成孤立专题、先看案例再忽略底座、只关注模型而忽视运行责任。这些问题在演示阶段不明显,因为演示通常只覆盖成功路径;上线后,用户会带来边界问题、重复请求、权限变化和长时间运行状态。平台团队应把失败样本纳入发布节奏,记录哪些样本需要阻断发布,哪些样本可以通过降级处理,哪些样本需要业务 owner 接受剩余风险。
读者可按角色选择路径,但应保留 Runtime、Trace、Eval 和治理章节的共同背景。这份记录不需要复杂,但要包含时间、版本、owner、样本、处置动作和下次复查条件。没有这些字段,复盘会停留在口头经验;有了这些字段,平台才能把一次问题转成后续发布、评测和培训材料。
平台可以从少量高风险场景开始。先选择调用量高、业务影响大或涉及敏感数据的路径,要求每次变更都留下证据包,再逐步推广到普通场景。这样章节里的能力不会停留在概念层,而会成为可运行、可解释、可退回的工程系统。
4.16 不同读者的取舍路径¶
全书地图还应给读者一个取舍路径。平台负责人可以先读第1章到第4章,再读 Runtime、Trace、Eval、安全和组织治理,因为这些章节决定平台能否规模化。数据负责人应重点读数据基础设施、知识工程和 DataAgent 主线,因为这些章节决定 Agent 能否拿到可信上下文。应用工程师可以从工具、Planner、HITL 和前端交互进入,但不能跳过 Trace 和发布证据,否则很容易做出能演示、难运营的应用。
取舍路径的意义在于降低第一次阅读的负担。读者不一定按顺序读完 55 章,但需要知道跳读会丢失什么。如果只读模型和 Prompt,会低估工具副作用、数据权限和成本治理;如果只读 DataAgent,会低估 Runtime、评测和合规证据;如果只读案例,会看不到案例背后的平台约束。目录应帮助读者形成这种预期,让后续章节的编号、图表和引用不显得零散。
不同读者可以采用不同路径,但主线必须清楚:模型能力进入平台,平台能力进入业务系统,业务系统再进入治理和运营。读者沿着这条线读,才能理解为什么本书反复写 Trace、Eval、Guardrails、owner 和发布证据。这些内容构成企业级落地的共同语言。
本章小结¶
第四章给出全书的阅读地图。模型路由对应推理层和成本管理,语义层对应 DataAgent 的数据依赖,Human-in-the-loop 对应企业责任边界,评测、安全和组织机制决定系统能否长期运行。这张地图的用法,是先定位问题发生在哪一层,再判断缺的是执行骨架、智能放大器,还是反馈系统。企业级 Agent 平台应先按四层定位,再看具体组件。八个能力簇提供后续章节的共同坐标。DataAgent 被选为主线,是因为它同时牵动模型、数据、工具、前端、评测和安全;其他业务场景也可以按同一套坐标拆解。后续章节从模型与推理层进入细节。模型并非平台中唯一的重心,但它是许多能力成立的起点,也最容易把早期试点推向真实成本、延迟和质量约束。
参考文献¶
Bass, L., Clements, P., & Kazman, R. (2021). Software Architecture in Practice. Addison-Wesley.
NIST. (2023). AI RMF 1.0.
OpenTelemetry. (n.d.). Documentation.
Model Context Protocol. (n.d.). Specification and documentation.